Salut Internet! ça faisait un bon moment que je n’étais pas sorti de ma cave pour publier un petit billet sur GTM. <Apparté pas forcément passionnant sur ma life> Lors de mon hibernation j’ai eu la chance d’aller suivre le bootcamp le Wagon afin de passer d’un niveau technique nul à un niveau technique un peu moins nul </fin de l’apparté pas forcément passionnant sur ma life>. Et au delà du fait de monter en compétence sur différents langages, j’ai surtout appris comment industrialiser l’orga de son code, que ça soit en Ruby, en JS, en CSS…
Mais quel rapport avec les Design Patterns d’ailleurs? Et c’est quoi, au juste, ces Design Patterns? Pourquoi le gars me parle de design alors que j’aime autant Photoshop que de manger des haricots verts?
OK, une prise de recul s’impose en effet pour savoir de quoi il est question. Contrairement à ce que leur nom laisse penser, les Design Patterns (il paraît qu’on peut dire « Patron de conception », mais nous allons nous abstenir dans le doute) sont tout simplement, dans le milieu du développement, des ensembles de conventions visant à organiser son code. Prenons par exemple le framework Ruby on Rails (cœur cœur) : celui-ci suit un Design Pattern dont vous avez probablement déjà entendu parler, à savoir MVC (Modèle – Vue – Contrôleur). Sans trop rentrer dans les détails, l’idée consiste à découper une app Rails en différents fichiers Ruby, en séparant strictement, via une convention d’arbo de fichiers, tout ce qui va toucher à l’affichage à proprement parler (la Vue, qui génère le HTML, concrètement), les données qui vont être transmises à cette vue (le Contrôleur), et les caractéristiques des objets qui vont être manipulés (les Modèles, donc, par exemple des articles de blogs, des produits, ou encore des utilisateurs), Rails se chargeant de faire communiquer tout ceci sans que vous ayez vraiment à connaître tous les détails.
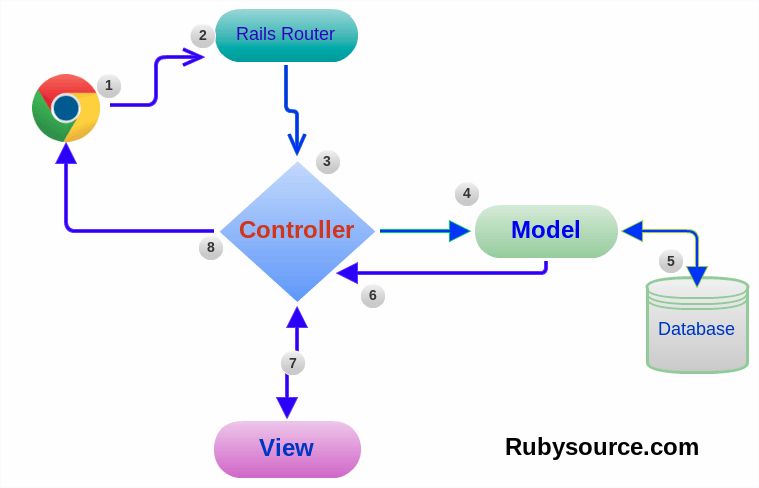
Même si bien comprendre ces Design Patterns nécessite un peu d’expérience, le bénéfice est immédiat, puisque n’importe quel développeur peut facilement retrouver à quel endroit du code modifier une feature. Le pattern MVC est très populaire, et utilisé par d’autres frameworks & langages (par exemple, Symfony en PHP), mais c’est loin d’être le seul qui existe. Voici par exemple un sympathique article qui en détaille quelques uns en JS.
GTM bien rangé, implémentation de qualité
Mais concrètement, qu’est ce que cela a à voir avec nos petites habitudes sur GTM? Vous allez très vite le comprendre. Je pense que vous vous êtes déjà retrouvés devant une des deux situations suivantes :
- Vous récupérez un container précédemment géré par une autre personne (agence, free lance, voire Satan dans certains cas, enfin d’après mon expérience), et vous passez plusieurs heures (jours, mois, années…) à détricoter ce qui a été fait, pour comprendre la logique d’organisation dudit container. Dans le meilleur des cas, ça se finit par un refacto en bonne et due forme avec votre logique (qui est forcément meilleure, parce que bon, voilà quoi, c’est la vôtre), ou bien (si vous manquez de temps), par un « ouais là je vais changer le tag ici, la variable là, un petit bout de trigger au fond à gauche, et avec un peu de bol, ça fera pas imploser le site dans 3 heures » (spoiler alert : ça le fera quand même imploser, mais dans un peu plus longtemps, en général entre 2 jours et 6 mois).
- Vous démarrez un nouveau setup et partez d’un container vierge. Bonne implémentation des familles, à base d’e-commerce, de tags Criteo, et d’app en Vue.js (allez, on se fait plaisir). Et là, on arrive à l’équivalent de l’angoisse de la feuille blanche chez le web analyste, à savoir que vous n’arrivez pas à trouver le compromis entre l’implémentation qui fonctionnera pour le lancement du site, ou bien quelque chose de très générique qui pourra potentiellement faire le job pour de futures évolutions
en facturant grassement votre client quand même.
Cet article va donc être une modeste tentative (puisque, à ma connaissance, ça n’a jamais été conventionné) de normaliser ceci, et de proposer un Design Pattern pour Google Tag Manager qui, basé sur mon expérience, me semble être facilement compréhensible, et très généralisable.
A noter que, inévitablement, je parle d’implémentation au sens large (pas uniquement de la partie setup GTM), puisque ce qui va être fait côté dèv sera parfois impacté. Et OUI, je pense même à toi (oui, toi, là, au fond) qui est obligé de faire du DOM scrapping, parce que ton client a un Joomla 1.6, updaté pour la dernière fois en septembre 2008, et que son chien (ou son agence média) a mangé les accès qu’il avait écrits sur un post it.
J’ai donc le plaisir de vous présenter le Framework NCT² (Natif – Calculé – Tags & Triggers), élaboré avec force et honneur en territoire breton indépendant.
Nous allons voir que ma longue digression (pour changer) ne fera finalement que parler autour d’un grand principe : Google Tag Manager est là pour transposer une logique Technique en logique Analytics, et clairement préserver la séparation des intérêts.
Oh wait, Separation of Concerns, ça ne serait pas un principe de dèv vieux comme le monde ? Eh ben si, et au fond, comme dirait Dieu Simo, « It’s Just Javascript ». Donc, si c’est du dèv, pourquoi pas, pour une fois, réfléchir comme des dèvs ¯\_(ツ)_/¯ ?
Cas pratique 1 : tracking des clics
Prenons un premier exemple concret ,avec une page de démo accessible ici que je vous incite vivement à garder dans un coin, et pour laquelle je vous invite à être tolérants question design : sur mes pages produits, un nouveau bouton « ajouter à la wishlist » va être implémenté, et mon product owner meurt d’envie de connaître le nombre de clics qu’il va générer. Histoire de compliquer un peu les choses, nous allons assumer que ce bouton existe à 2 endroits de la page (disons « top » et « bottom »).
Comme je suis un webanalyste sérieux, je vais implémenter ceci dans les règles de l’art (et documenter comme il faut). Je veux donc remonter un event GA au clic sur l’un de ces 2 boutons selon la nomenclature suivante :
- Event category : « Clic Wishlist » (valeur constante)
- Event action : position du bouton (« top » ou « bottom ») : afin de simplifier les choses, nous allons prendre directement l’ID des boutons, qui, par miracle, correspond exactement à ces valeurs (le dèv qui a bossé sur cette page est un gars très pro).
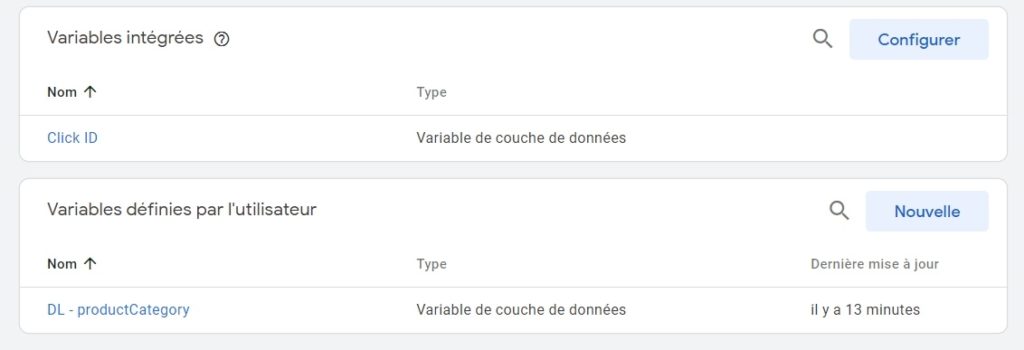
- Event label : catégorie de produit de la page, qui se trouve être présent dans le data layer (clé productCategory).
Pour les webanalystes chevronnés que vous êtes, ce genre de chose ne pose pas vraiment problème, mais voyons comment faire les choses de façon efficace et ordonnée, ce qui va naturellement nous amener à NCT².
1/ Pour commencer, nous allons créer 2 variables (je ne vous fais pas l’injure de vous montrer comment faire dans le moindre détail, en principe vous savez faire, ou alors allez jeter un œil à mon tuto pour débutants) :
2/ Ensuite, un petit trigger des familles pour écouter les clics qui vont bien sur la page en question :
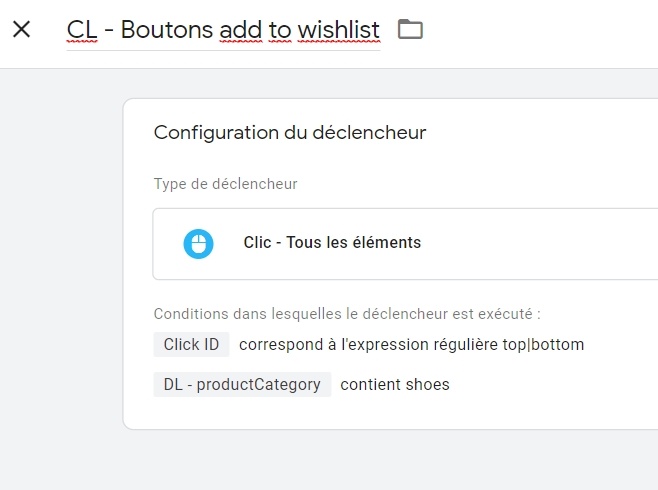
A noter que j’utilise ici une condition sur le data layer pour « renforcer » mon trigger, mais que ce n’est nullement obligatoire.
3/ Enfin, on créé le tag d’event GA en accord avec nos specs, et on lui attache le trigger pour finaliser notre petite cuisine :
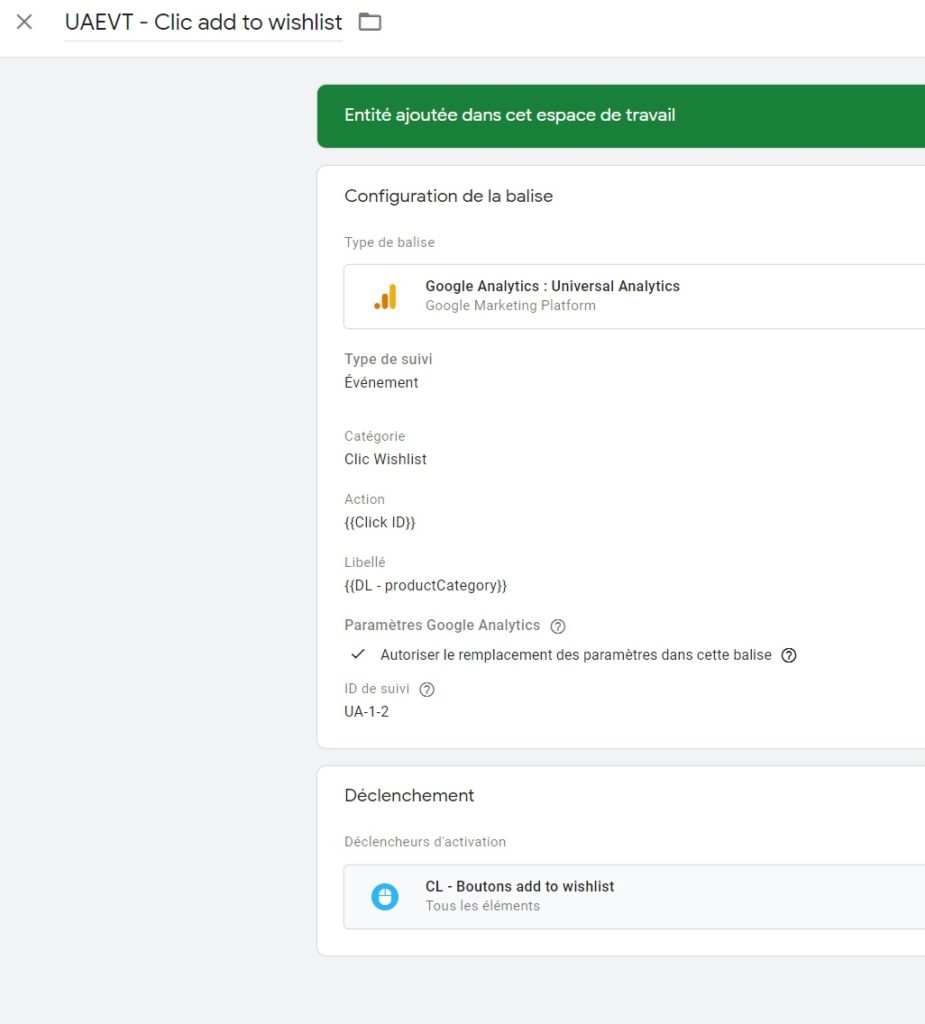
Au cours du process, nous allons évidemment tester que les variables remontent correctement, puis que les clics sont bien déclenchés, et vont populer les valeurs qui vont bien dans l’event.
Jusqu’ici, vous allez me dire que je n’ai rien fait de bien révolutionnaire. J’ai créé des variables, puis des triggers et tags utilisant ces variables (simplement les 3 briques de GTM), ce que vous faites sans doute déjà au quotidien.
Cas pratique 1 bis : Tracking des clics, option product owner relou
Maintenant, compliquons un peu les choses. Imaginons que pour une raison mystérieuse, vous vouliez changer la nomenclature des events :
- Pour ce qui est de l’event action, on voudrait enrichir « top » et « bottom » par la couleur du bouton en front (oui, votre product owner est un féru d’expérimentations burlesques), de façon à obtenir quelque chose comme « top – bleu » et « bottom – rouge ».
- Au lieu de « shoes » en event label, vous voulez un libellé en bon français, à savoir « chaussures ». MAIS (parce que sinon ça serait trop simple), le libellé ne doit être traduit que si on est sur une page du site .com (oui, parce que je vous l’apprends, notre site fictif existe en .fr et .com, faites un peu preuve d’imagination, bordel).
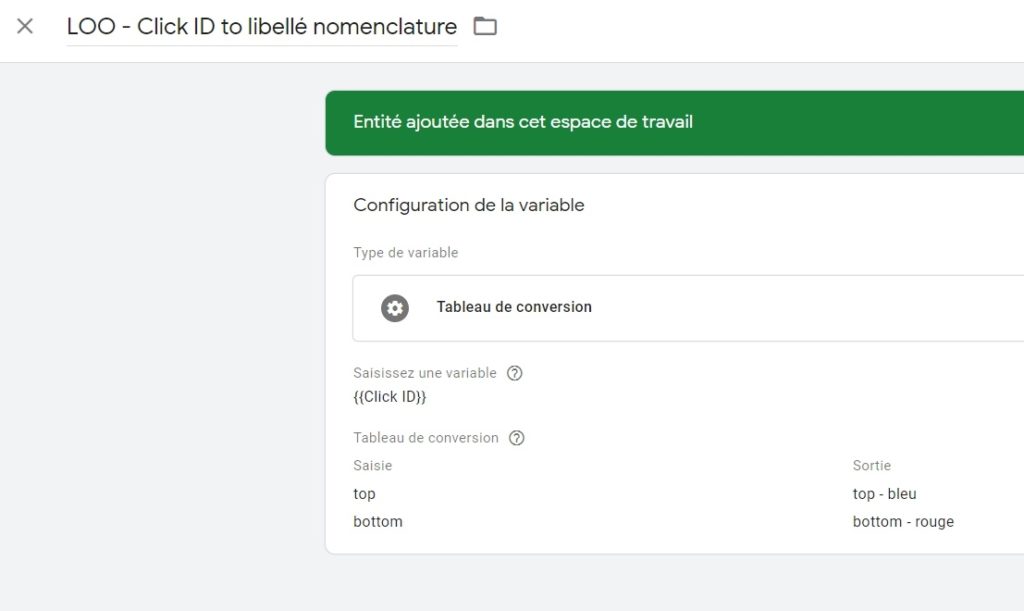
Le premier cas est assez simple à gérer. Une petite lookup va en effet parfaitement faire le job :
Le deuxième cas est volontairement plus touffu, pour vous forcer à faire un peu de JS custom :
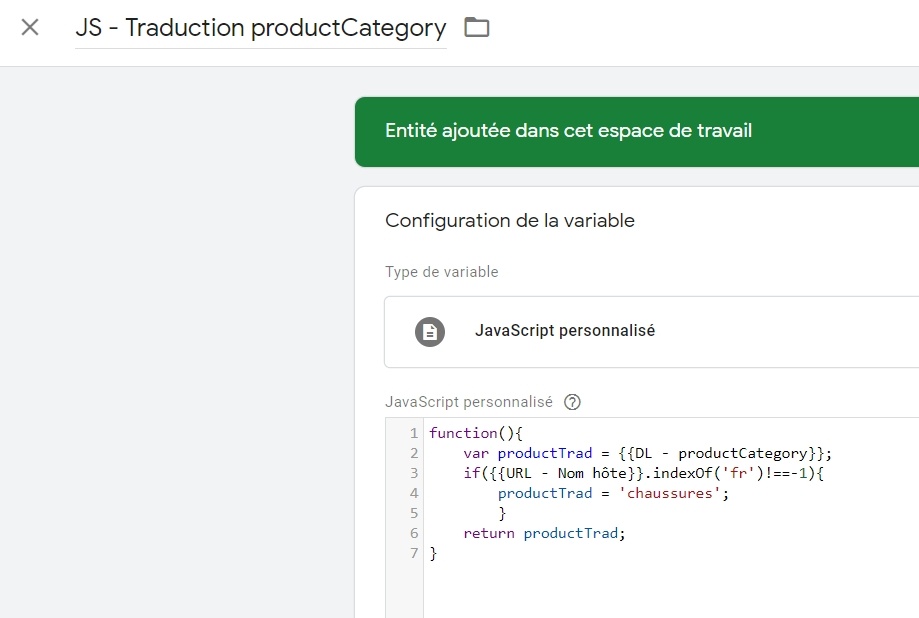
function(){
var productTrad = {{DL - productCategory}};
if({{URL - Nom hôte}}.indexOf('fr')!==-1){
productTrad = 'chaussures';
}
return productTrad;
}(à noter que ça peut aussi se régler avec un tableau de Regex, mais autant varier les plaisirs).
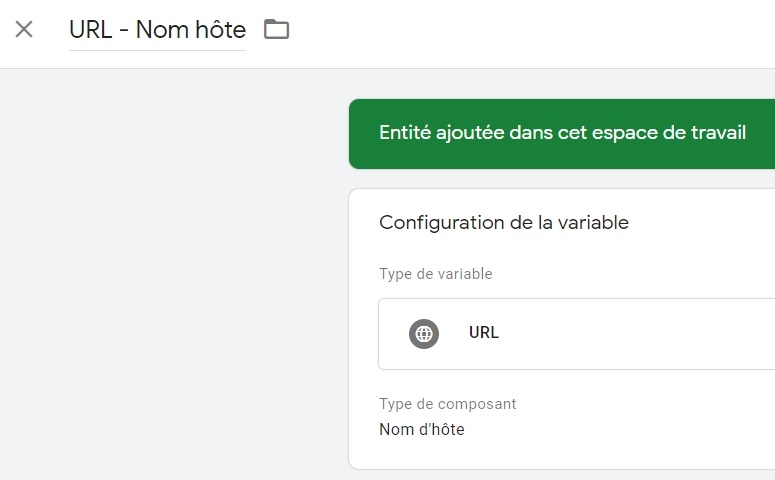
On note également que j’ai créé puis immédiatement utilisé une variable native {{URL – Nom d’hôte}}, que je vous montre au cas où :
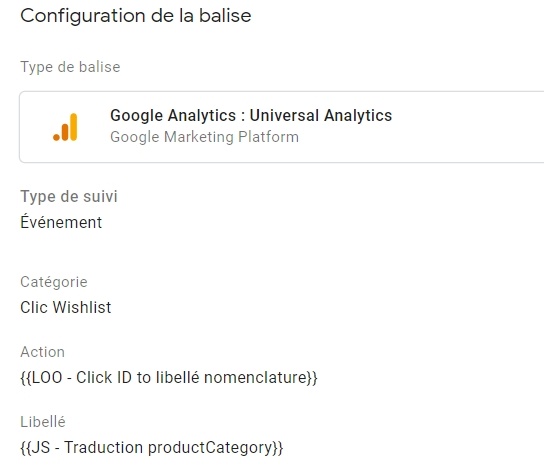
Il ne reste donc plus qu’à revenir dans notre event GA et à modifier les variables appelées avec ce que l’on vient de créer :
Alors. Pourquoi vous avoir montré des choses un peu tordues, et surtout compliqué les choses? Eh bien je vous ne le fais pas dire : nous avons introduit une nouvelle couche, qui à mon sens manque à pas mal d’implémentations que j’ai pu croiser lors de mes pérégrinations : la couche de calcul, qui va donc venir enrichir / compléter / réinterpréter les données que l’on récupère depuis le front du site.
Digression rageuse incomming
Et c’est là que nous allons en profiter pour glisser vers un grand débat existentiel des penseurs de l’implémentation GTM (eh ouais les gars, on est 12 et on est super fiers) : « Pourquoi ne pas directement demander au développeur de mettre ces données dans le data layer? » Comme ça, on a un container GTM qui ressemble à ça :
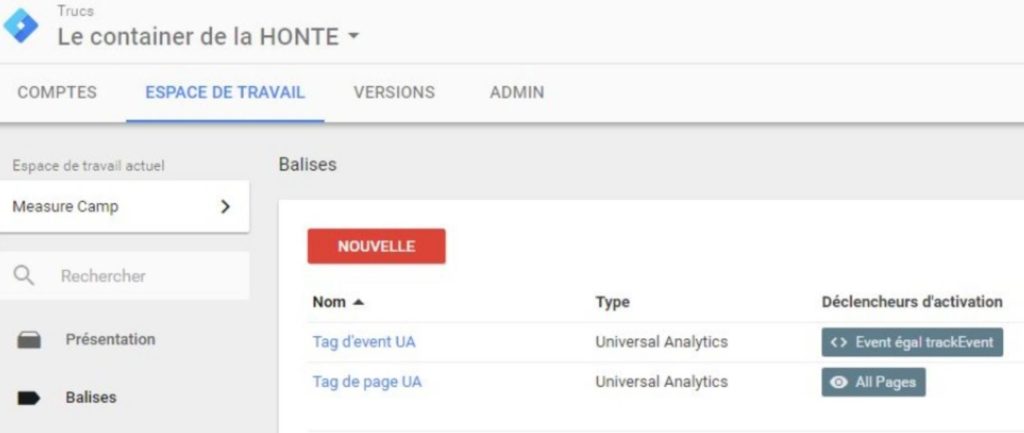
(oui le screenshot date un peu, je l’ai honteusement recyclé d’une vieille présentation faite au MeasureCamp Nantes 2016)
C’est précisément à ce moment que je commence à m’énerver tout rouge.
Pourquoi tout rouge? Parce que ce genre d’implémentation fait en réalité perdre tout intérêt à GTM, puisqu’on demande en réalité à nos gentils développeurs de porter une logique qu’ils ne connaissent pas : ils ont sincèrement mieux à faire que savoir ce que c’est qu’un event category GA ou l’index de votre custom dimension.
La séparation des intérêts, you know? Eh bien nous sommes clairement dedans. Et il n’y a pas de « ouais moi je sais pas faire de Javascript lol » qui tienne, nom d’une pipe!
Vous commencez à saisir le truc?
Cas pratique 2 : Tag presque conforme à la RGPD
Nous allons maintenant légèrement sortir de notre univers très « GA Centric » pour voir que le concept est totalement applicable à tout type de tag.
Voici une situation que vous avez dû également connaître : votre agence média vous envoie un superbe fichier Excel (Excel 2003 hein, on est pas fous les gars), qui contient 283 tags « Ouais Beau Rama » à poser d’urgence sur le site du client (qui est complètement d’accord et oui promis juré craché leur juridique a bien validé que les tags respectaient la vie privée des utilisateurs et n’allaient pas miner du Bitcoin en scred).
Après quelques minutes d’investigation vous vous rendez compte que, comme prévu, les 283 tags en question sont en réalité identiques, à une variable près :
<script type="text/javascript" src="http://webaurama.com/piggybackingSecretDoNotOpenLol.js"></script>
<script type="text/javascript">
var accountID = '123435',
productID = //Remplir ici avec une des 283 lignes. A vous de trouver laquelle mdr
</script>Le fameux productID étant donc, d’après votre sagacité légendaire, déductible, par exemple, de l’URL. Sachant que les URLs du site de votre client ont un pattern du type siteclient.com/products/productID/detail, il est simple d’aller splitter l’URL, d’isoler le product ID, et de faire une petite table de correspondance.
Allez, c’est parti, faisons donc ça couche par couche.
Première couche de variables : on se fait la petite variable native pour récupérer l’URL, ou plutôt l’URI (le « chemin » comme l’appelle GTM en version française) :
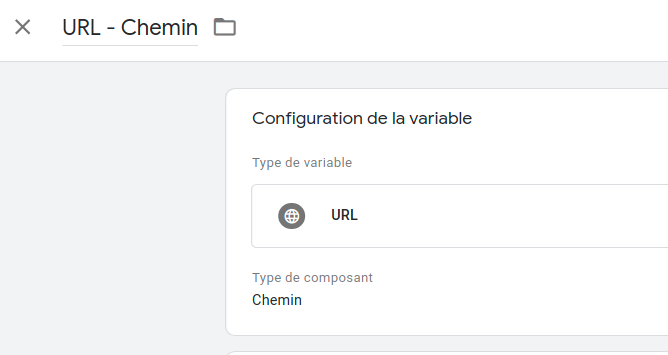
Ensuite, couche 2, le calcul : un petit script du charisme pour récupérer le product ID depuis l’URI sus-mentionnée :
function (){
return {{URL - Chemin}}.split('/')[1];
};(évidemment, je simplifie légèrement les choses en partant du principe que toutes les URLs du site ont ce pattern. On pourrait ajouter des couches de contrôle & cie, mais cela compliquerait et n’apporterait rien à cet exemple).
Ensuite, ne reste plus qu’à faire une petite lookup qui va bien (2ème couche de calcul) pour passer du product ID à l’ID du tag de pub :
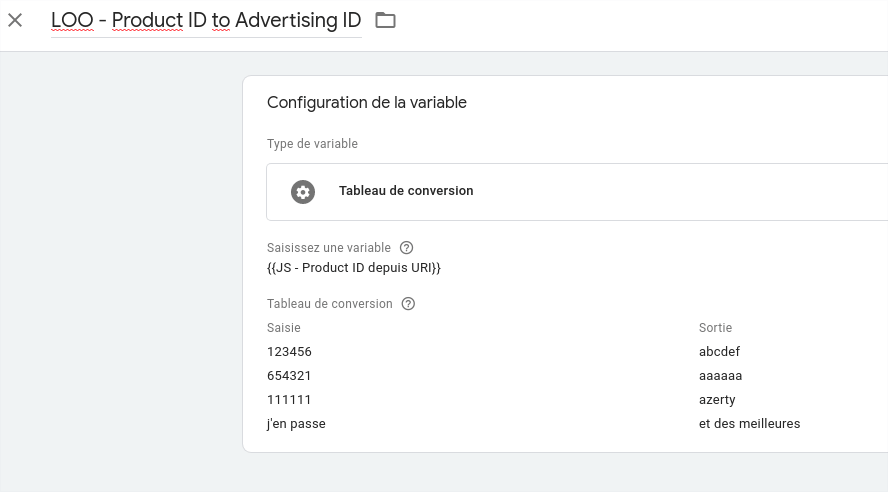
Et enfin, on va créer notre tag à proprement parler en lui passant notre variable :
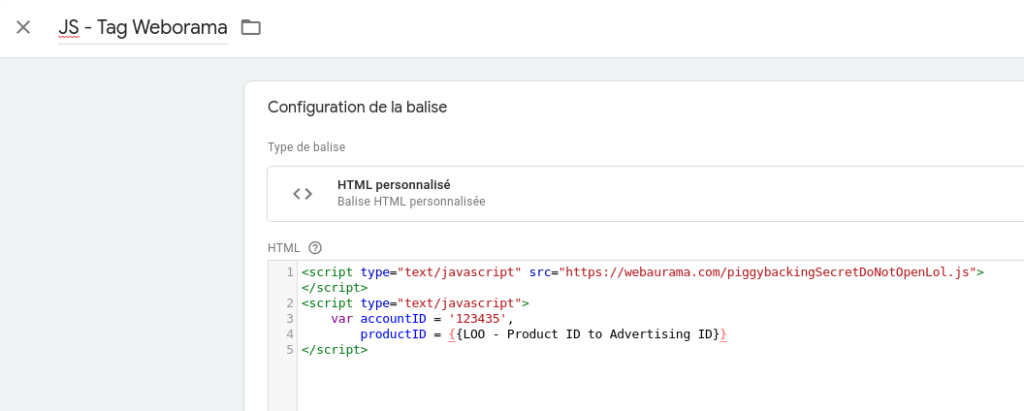
La couche de calcul est l’intermédiaire entre la logique technique et la logique de tagging, ce qui donne une vraie flexibilité qu’on attend d’un outil comme GTM. Cela va aussi énormément faciliter le débug, puisque grâce au volet de preview, vous pouvez facilement voir à quel endroit (la couche native ou la couche de calcul) quelque chose peut partir en sucette.
C’est aussi une façon très intuitive et naturelle de préparer son setup :
- On récupère les variables natives dont on a besoin (composants d’URL, data layer…).
- On fait les calculs depuis ces variables natives, ce qui est en général la phase la plus longue, surtout s’il y a besoin de faire du JS.
- On créé tag & trigger en allant y insérer les variables sus-crées.
Si on teste soigneusement via le volet de preview à chaque étape, cela diminue drastiquement les chances de faire des erreurs.
Allez, vous commencez à être chauds? Troisième exemple :
Cas pratique 3 : Date de publication
Si vous travaillez sur un site éditorial, une information fondamentale à remonter dans votre outil d’analytics est la date de publication d’un contenu, qui va classiquement venir se nicher confortablement dans votre data layer.
Or, lorsqu’on creuse un peu les analyses liées à ce sujet, on se rend compte qu’il est vite crucial de disposer de différentes granularités pour pouvoir segmenter par jour de publication, par heure de publication, voire de séparer semaine et WE, etc…(oui, j’ai GA360, je suis riche et je vous méprise).
Avez-vous vraiment envie de demander à vos développeurs de vous pousser CINQ attributs dans le data layer? La réponse est non.
Étant donné ce que l’on a vu juste au dessus, il est évident qu’il est nettement plus simple de demander un simple timestamp (qui sera notre Base), sur laquelle nous allons faire différents Calculs en JS (heure de publication, jour de publication, WE ou non…), avant de router ça proprement via des Tags&Triggers.
Cette fois, je ne vais pas vous faire toutes les étapes, mais partons du principe que nous avons un timestamp dans un attribut data layer « datePublication ». Après avoir créé la Base via une classique variable…
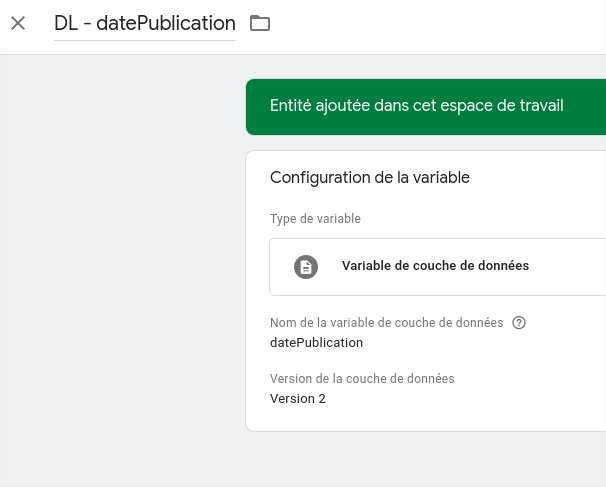
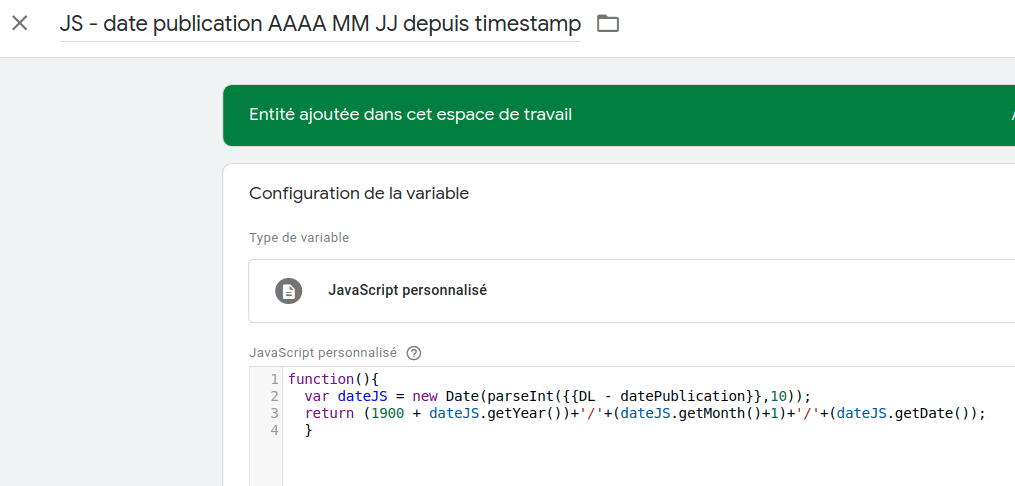
…nous allons par exemple récupérer ce timestamp pour le convertir au format AAAA-MM-JJ via une variable de Calcul :
function(){
var dateJS = new Date(parseInt({{DL - datePublication}},10));
return (1900 + dateJS.getYear())+'/'+(dateJS.getMonth()+1)+'/'+(dateJS.getDate());
}
Je ne vais pas vous la faire, mais le principe est exactement le même pour remonter uniquement l’heure, le jour ou autre, et ensuite, caller ceci dans une custom dimension GA, une cVar Content Square, ou n’importe quelle information qui va venir enrichir un tag quelconque.
Récapitulatif
On pourrait multiplier les exemples à l’infini, cette technique est valable pour tout ce que vous faites dans GTM : implémentation enhanced e-commerce, tracking de clics ou d’interactions en AJAX, technos de SPA type Vue ou React… L’intérêt est que vos développeurs ne portent qu’une logique technique qui (on l’espère en tout cas) leur parle. Et si demain vous décidez de passer de GA à Adobe Analytics ou encore Matomo, cela devrait pouvoir se faire quasiment sans dèv, ce qui vous donne mécaniquement 37 points de Karma.
Même si vous faites du scrapping, vous ne faites finalement que remplacer la couche Native par une couche de Scrapping (SCT² , ça passe carrément). Et finalement, vous n’aurez qu’un petit (ou pas) risque supplémentaire, à savoir que le sélecteur CSS que vous utilisez ne fonctionne plus, mais bon, on ne peut pas avoir le beurre et l’argent du beurre.
Alors oui, vous devez faire l’effort de comprendre comment fonctionne votre CMS ou techno maison. Non, vous ne pouvez plus écrire une spec du genre « renseigner le type de page dans le data layer » sans discuter avec un interlocuteur technique. Peut–être que votre devis à base de « oui t’inquiète cousin ça sera Z-É-R-O dèv avec moi, je ne parle pas avec ces individus » était un peu une escroquerie. Mais bon, promis, vous ne recommencerez plus, hein? Hein? HEIN?
Après réflexion, et pour les plus techos d’entre vous, on se rend compte qu’après réflexion, NCT² est finalement assez proche de la logique MVC, puisque, dans les 2 cas, on se base sur une structure de données (les modèles en MVC, le data layer dans notre cas), et qu’on ne fait que les manipuler dans une optique qui est fonctionnelle en MVC (afficher des pages web), et analytique pour NCT² (remonter des données dans différents tags). D’ailleurs, si on devait être super meta, c’est finalement du bon sens de penser que si un site utilise un framework MVC, les données déversées dans le data layer seront très probablement issues des modèles de votre app. En tout cas, je vous laisse réflechir là-dessus.
Est ce que que cela vous parle? Avez-vous déjà eu affaire à des implémentations inmaintenables? Utilisez-vous ce genre de méthodo? Comme d’habitude, n’hésitez pas à rebondir dans les commentaires et sur Twitter, avec bienveillance et indentation de 5 espaces, cela va de soi.
J’espère que vous avez aimé lire cet article, je vous dis à la prochaine. Tendreté, love, et beurre salé.
Merci Aristide pour le partage !
Je suis intermédiaire d’où ma question dans le cas 2, comment faut-il intégrer la couche de variable 1 ? Je ne vois pas d’image
Effectivement, j’avais oublié l’image, c’est corrigé, merci pour ton commentaire!
Encore un contenu de qualité ! Merci Monsieur Aristide !
Merci Frédéric!
Hello Aristide,
Très bel article, comme d’habitude ! Ca fait plaisir de te lire 🙂
C’est sûr que, bien structurer les configurations dans GTM facilite le travail pendant l’implémentation et pour le maintient, mais aide également à la réflexion du conception de tracking.
Très intéressant le lien vers l’école de coding que tu as partagé tout en début. Je réfléchie à m’inscrire…
A bientôt !
Tatiana
Merci Tatiana! N’hésite pas à me contacter si tu veux des infos sur Le Wagon, c’était vraiment une super expérience pour ma part pour me « débloquer » sur certains sujets techniques!