Lorsqu’on s’intéresse à un site éditorial (forcément, mon passé récent chez Ouest France est un tout petit peu lié à ça), un axe d’analyse qui est toujours d’un grand intérêt est la récence du contenu.
En effet, de tous temps depuis le début des Internets, toute bonne newsroom qui se respecte a voulu avoir une réponse à ce type de question :
- « Est ce que les articles performent longtemps après avoir été publiés? »
- « Est ce que les articles écrits le soir performent mieux que ceux écrits le matin? »
- « Quel est mon nombre de pages vues consolidé par mois / semaine de publication? »
Nous allons voir comment répondre à toutes ces questions
Le setup technique
Puisqu’on est entre personnes de bon goût, nous allons démarrer par la partie technique. Le non initié à Google Tag Manager pourrait penser que les questions sus-mentionnées donneraient lieu à de nombreux attributs dans le data layer, qui devraient faire l’objet d’une expression de besoin, éventuellement arbitrée en réunion de priorisation, avant de passer dans le bac de culture du scrum master, qui lottirait ensuite en 17 tâches Jira. Ah, c’est beau, l’agilité.
Eh bien NON les amis. Nous allons travailler à partir d’un simple attribut que votre cher développeur va bien gentiment vous déverser dans le data layer, à savoir la date de publication de l’article. Mais pas n’importe comment. Sous la forme d’un timestamp Unix.
Pour les non initiés, un timestamp Unix, (ou encore heure Unix en bon français) représente à un instant T le nombre de secondes écoulées depuis le 1er janvier 1970. Il s’agit de la méthode utilisée par la plupart des langages de programmation pour faire des calculs temporels (encore qu’en .NET je suis sûr qu’ils doivent compter en années fiscales parce que ça fait plus corporate). Concrètement, le timestamp d’à peu près le moment où j’écris cet article est 1585526400. Enfin 1585526401. Non, plutôt 1585526402. Enfin bref, vous voyez l’idée.
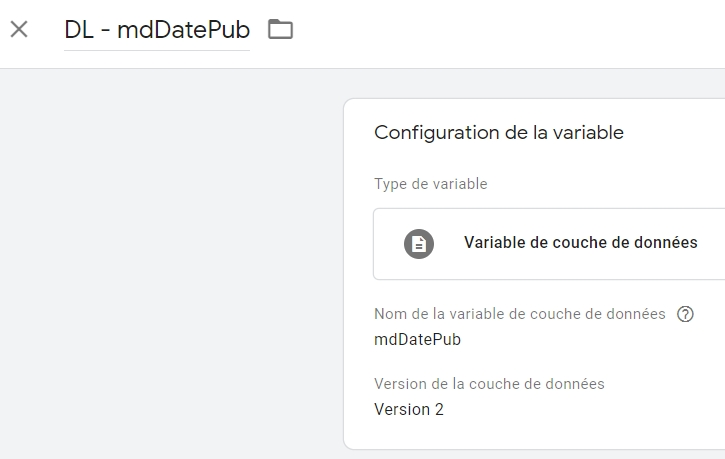
Notre développeur préféré va donc intégrer cette valeur dans un attribut data layer, par exemple ici mdDatePub :

On créé ensuite la variable côté GTM…
Et on vérifie via le volet de preview qu’elle remonte telle qu’on l’attend :
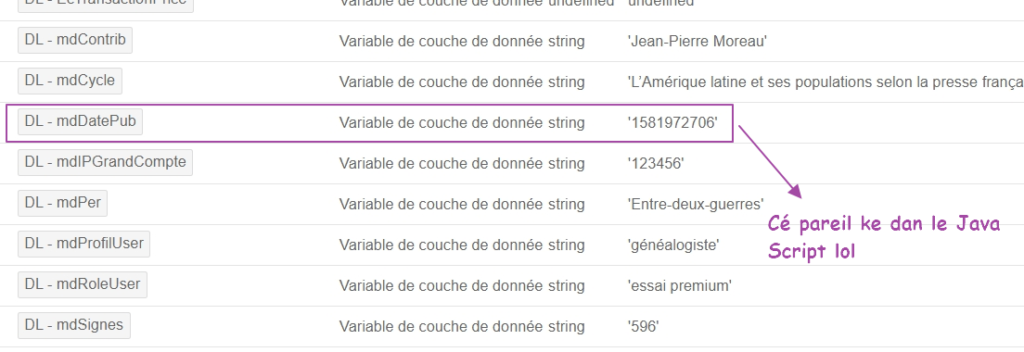
Donc un timestamp, c’est bien joli, mais malheureusement, très peu de newsrooms sont capables de faire la conversion entre un timestamp et une date calendaire (« Hé, Michel, t’as vu cet article du 1583798400? Un succès tonitruant! » « Hé, mais comment tu me parles? On est plus dans les années 3155 mec »).
Donc il va falloir travailler un peu ceci, et donc faire un peu de Javascript!
La transformation de la date
Le premier format auquel on pense va être quelque chose pour bien « ranger » nos dates sera quelque chose comme AAAA-MM-JJ (par exemple, 2020-04-01). On va donc passer du timestamp à ce format via une bonne petite variable en JS custom :
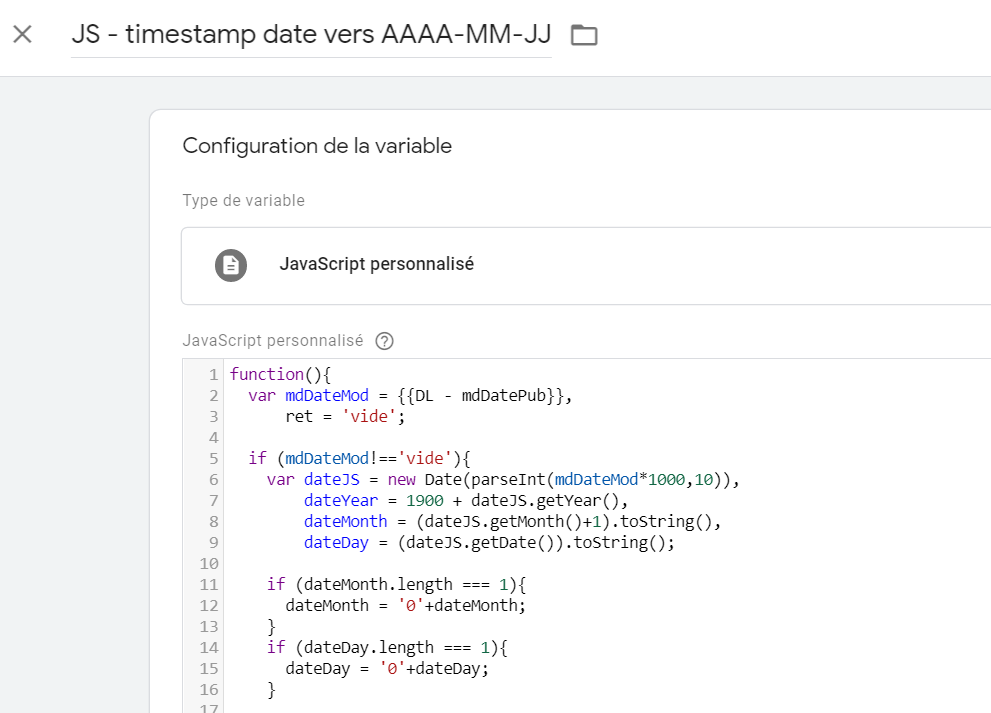
Voyons de quoi il en retourne côté JS :
function(){
var mdDateMod = {{DL - mdDatePub}},
formatedDate = 'vide';
if (mdDateMod!=='vide'){
var dateJS = new Date(parseInt(mdDateMod*1000,10)),
dateYear = 1900 + dateJS.getYear(),
dateMonth = (dateJS.getMonth()+1).toString(),
dateDay = (dateJS.getDate()).toString();
if (dateMonth.length === 1){
dateMonth = '0'+dateMonth;
}
if (dateDay.length === 1){
dateDay = '0'+dateDay;
}
formatedDate = dateYear+'-'+dateMonth+'-'+dateDay;
}
return formatedDate;
}Prenons les choses une par une, vous allez voir, ça va bien se passer.
Digression importante incoming : même si je spoile un peu la suite, je pars du principe que cette valeur ira, ô grande surprise, alimenter une custom dimension de scope hit. Et une custom dimension de scope hit doit être alimentée sur l’ensemble des pages, y compris lorsqu’elle n’est pas « valorisable », auquel cas on envoie une valeur par défaut. Par exemple, « vide » (vous pouvez aussi mettre « bouillabaisse », si ça vous fait plaisir, je ne juge pas). Pourquoi? Parce que si vous voulez faire un segment du type « session contient valeur X pour une CD de scope hit », si vous ne populez pas la CD en question sur tous les hits, GA renverra un peu n’importe quoi.
Bon, fin de l’apparté, nos 2 variables JS sont settés : l’une, « mdDateMod », qui va récupérer ce que nous renvoie le data layer, et l’autre, « formatedDate », qui sera notre valeur de retour, et pour laquelle on définit « vide » en tant que valeur par défaut :
var mdDateMod = {{DL - mdDatePub}},
formatedDate = 'vide';Ensuite, on rentre dans la grosse boucle du script, où on va retraiter notre timestamp Unix s’il est présent dans le data layer :
if (mdDateMod!=='vide'){
var dateJS = new Date(parseInt(mdDateMod*1000,10)),
dateYear = 1900 + dateJS.getYear(),
dateMonth = (dateJS.getMonth()+1).toString(),
dateDay = (dateJS.getDate()).toString();
if (dateMonth.length === 1){
dateMonth = '0'+dateMonth;
}
if (dateDay.length === 1){
dateDay = '0'+dateDay;
}
formatedDate = dateYear+'-'+dateMonth+'-'+dateDay;
}La variable « dateJS » sert, avec le « new Date », à avoir une date cette fois au format JS classique (quelque chose comme « Sun Dec 17 1995 03:24:00 GMT… »). On pense à passer à la moulinette « parseInt » la valeur que l’on récupère depuis le data layer, à savoir passer d’une string à un integer (oui, parseInt prend 2 paramètres, le 2nd étant 10 pour bien préciser qu’on transforme en entier sur une base décimale). A noter que vous pouvez aussi demander à avoir directement un integer dans le data layer, et vous passer de la conversion. C’est vous qui voyez.
« dateYear », « dateMonth » et « dateDay » permettent respectivement de récupérer l’année, le mois, et le jour (sans déconner?) avec les méthodes getYear & cie, qui font exactement ce qu’on leur demande. Ah, en fait, pas tant que ça. getYear renvoie l’année moins 1900. Parce que pourquoi pas. Et getMonth démarre à 0. Parce qu’on est en informatique. On commence toujours à compter à 0.
A noter que si vous êtes peu à l’aise en JS, n’hésitez pas à vous arrêter ici, et à déjà faire un « return » en concaténant ce que retournent ces 3 variables, afin de voir ce que cela retourne (vous l’avez? Vous l’avez?) :
return dateYear+'/'+dateMonth+'/'+'dateDay'De façon générale, peu importe ce que vous cherchez à faire, dés que vous êtes un peu perdus dans votre script, ayez tout le suite le réflexe de mettre ça dans un return pour voir de quoi il en retourne.
Ne reste plus qu’à faire un petit check de précaution sur « dateMonth » et « dateDay » : si on n’a qu’un seul caractère, on le préfixe par un « 0 » (bah oui, on veut du AAAA-MM-JJ, pas du parfois AAAA-MM-JJ, parfois un peu du AAAA-M-JJ, et de temps en temps du AAAA-MM-JJ
Une fois tout ceci fait, on donne ceci à manger à notre variable, et si tout se passe bien, on a bien une valeur dans le format espéré, ce dont on va s’assurer via notre habituelle preview :

On se dépêche de remettre ceci à sa place, à savoir dans une custom dimension de scopt hit…
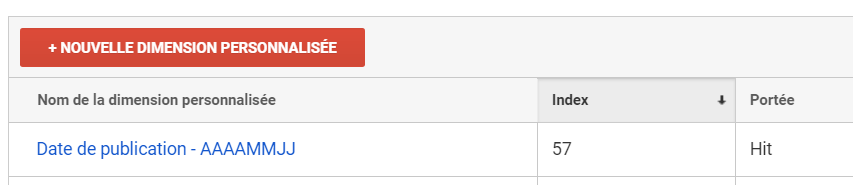
… qui va sagement aller se garer dans notre variable « GA Settings » :
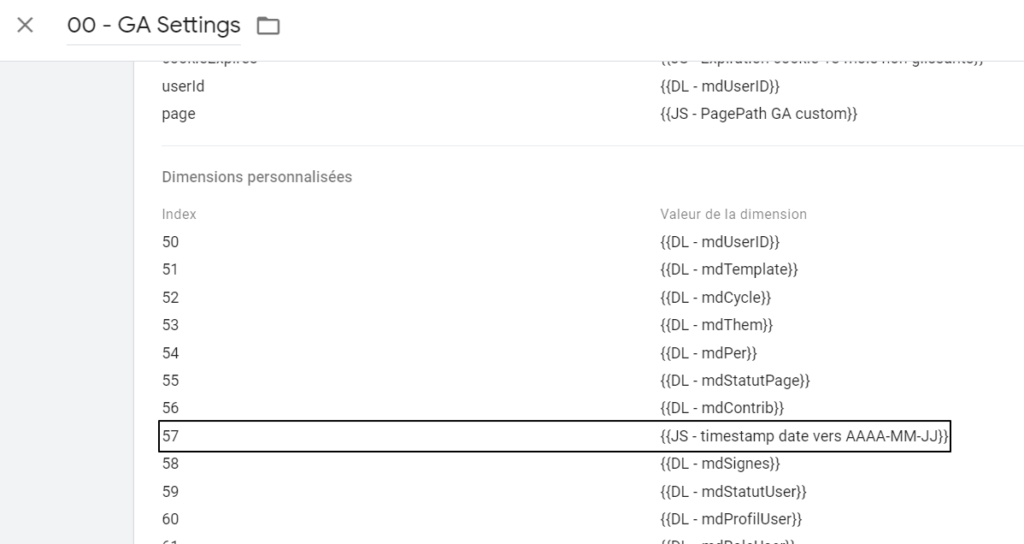
(oui, j’ai pris l’habitude de la préfixer ma variable GA Settings par « 00 » dans mon nommage de variables pour qu’elle remonte en premier, sachant que j’y touche en général pas mal ça fait toujours gagner un peu de temps)
Une fois que vos gentils utilisateurs autont désactivé leur Ublock généré quelques pages vues, vous devriez si tout se passe bien être dans la capacité de faire un custom report de ce type :
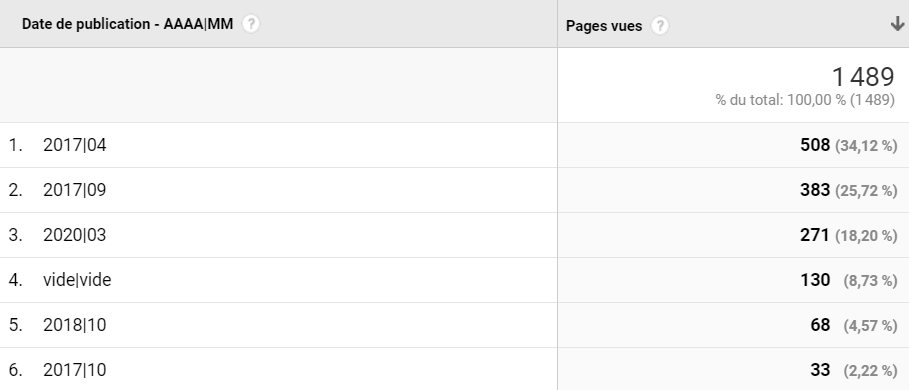
Alors oui, j’entends d’ici vos sarcasmes : « non mais attends, tu nous parles de AA-MM-JJ, et tu nous sers du AAAA|MM, nan mais allô quoi, on est en agence média ou quoi, ici? ».
Raison absolument pas justifiable : ce screenshot provient de mon blog, où je suis assez lucide quant à ma production famélique de contenu (mais toujours de qualité). Donc je me suis arrêté à une consolidation au mois.
Je pense que vous avez donc compris l’idée : grâce à cette formidable custom dimension, vous allez être en mesure de voir, sur une période X, le nombre de pages vues, temps passé, taux de sortie & cie, pour du contenu *produit sur un jour donné*.
Je ne vais pas vous la faire 50 fois, mais à votre convenance, libre à vous de modifier la valeur de sortie : si vous avez une rédaction qui produit beaucoup vous pouvez aller beaucoup plus dans le détail, et avoir une custom dimension « heure de publication ». Le principe est le même, si ce n’est qu’on utilisera la méthode getHours() en JS.
On peut aussi imaginer faire une règle du type « matin vs après-midi », ou encore « semaine vs week-end » (ou les rythmes de production ne sont en général pas les mêmes).
Bon, et après, si vos journalistes vous demandent si le contenu qui est publié sur les heures paires performe mieux que celui sur les heures impaires, dites leur que Kev Adams aurait une relation secrète avec Kilian Mbappé, ça devrait les occuper (même si en vrai vous pourriez le faire, rien de plus facile que de savoir si un nombre est pair ou impair en JS).
Le calcul dynamique de l’âge de l’article
Analyser la consommation sur une période donnée est intéressant : sur la semaine du 1er au 7 janvier, après quelques tours de magie sur Google Sheets / Excel, je vais être capable de savoir si les articles qui performaient étaient ceux de la même semaine, de la semaine précédente, etc… Mais si je veux la même chose pour la semaine suivante, je dois me repalucher le travail. Et c’est bien connu, le repaluchage, c’est très surfait. Donc nous aimerions bien avoir une vision agrégée de l’âge moyen d’un article au moment de sa lecture.
Une petite idée? Allez, je vous invite à prendre 2 minutes et à ne pas lire la suite immédiatement. Avez-vous une idée de la façon dont on pourrait procéder pour récupérer cette information sans ajouter d’attribut au data layer?
En attendant, et pour ne pas trop vous tenter, je vous invite à réfléchir en regardant ces images de Julien Lepers.



Ça y est, vous avez trouvé? Ouah, vous l’avez déjà mis en prod? Bravo, quelle rapidité! Ah, vous voulez quand même la solution? Bon, OK. Je vais vous présenter la variable JS custom que l’on va utiliser. Et histoire de rendre ça fun, on va faire ça en 2 temps, en optimisant à fond notre code. Premier temps, donc :
function(){
var ageArticle = 'vide'
if( {{DL - mdDatePub}} !=='vide' ){
var currentTimestamp = Date.now();
var articleTimestamp = parseInt({{DL - mdDatePub}},10);
var diffMS = currentTimestamp - articleTimestamp;
var diffDays = diffMS/1000000/60/60/24;
var diffDaysRound = Math.round(diffDays);
}
return diffDaysRound;
}On progresse ici pas à pas :
- Comme pour la variable précédente, on ne rentre dans notre boucle que si la date de publication est valorisée dans le data layer.
- Les variables JS « currentTimestamp » et « articleTimestamp » servent à récupérer le timestamp courant et celui de l’article, sous forme d’integer.
- « diffMS » calcule la différence entre les 2 timestamps…
- …que « diffDays » convertit en jours (les divisions successives servent à passer en secondes, puis minutes, puis heures, puis jours).
- Et enfin, « diffDaysRound » arrondit cette variable à l’entier le plus proche (on aurait pu faire un Math.floor pour arrondir à l’entier inférieur, à vous de voir).
- Et on finit par tout simplement retourner cette variable.
Pas de surprise, on retrouve bien ce que l’on attendait dans la preview :

Je ne vous refais pas tout le setup de rentrer ceci dans une custom dimension, de faire le custom report dans GA, & cie, c’est exactement la même chose que pour le formatage de la date.
Le script ci-dessus fait parfaitement le job, vous pouvez tout à fait passer ça en prod demain matin, aucun souci, ça remontera parfaitement. Mais puisque je suis un peu maniaque et consciencieux, faisons gagner quelques nano secondes à notre script en lui faisant subir un petit régime :
function(){
return ({{DL - mdDatePub}}!=='vide'?Math.round((Date.now()-(parseInt({{DL - mdDatePub}},10)))/8.64E+10
):'vide');
}Tout pareil, en une seule ligne, qui fait astucieusement appel à un ternaire pour gérer notre vérification de la « vacuité » de la valeur initiale, ainsi que de l’écriture scientifique pour la conversion des millisecondes aux jours. Après, ce n’est pas forcément le top en termes de lisibilité. A vous de voir ¯_(ツ)_/¯
Scrapper le DOM? Assurément!
Alors bien évidemment, je vous sens tous frétillants derrière votre écran, mais j’en ai bien conscience, votre prochaine mise en prod aura peut-être lieu sur Q2 2024 parce que vous devez d’abord mettre plus d’interstitiels et que Taboola a sorti un nouveau format disruptif (il faut bien manger hein). Bien évidemment, il reste possible de récupérer la date de publication en scrappant le DOM, si tant est que la date apparaisse quelque part en front.
Si je prends l’exemple de mon blog, la date apparaît bien proprement juste en-dessous du titre de l’article :
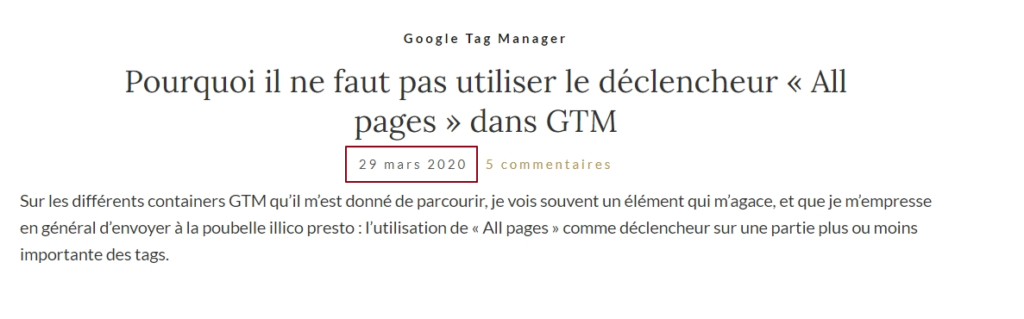
Je ne sais pas pour vous, mais la persective d’aller faire une table de correspondance entre les mois en français et un timestamp JS ne m’enchante pas. Regardons donc du côté du HTML :
<time class="entry-date" itemprop="datePublished" datetime="2020-03-29T23:45:46+02:00">29 mars 2020</time>On est d’accord, cet attribut « datetime » nous fait un peu de l’œil? Un petit check-up dans la console nous permet de nous assurer qu’on a quelque chose d’intéressant :

Callons tout ceci bien proprement dans une variable GTM :
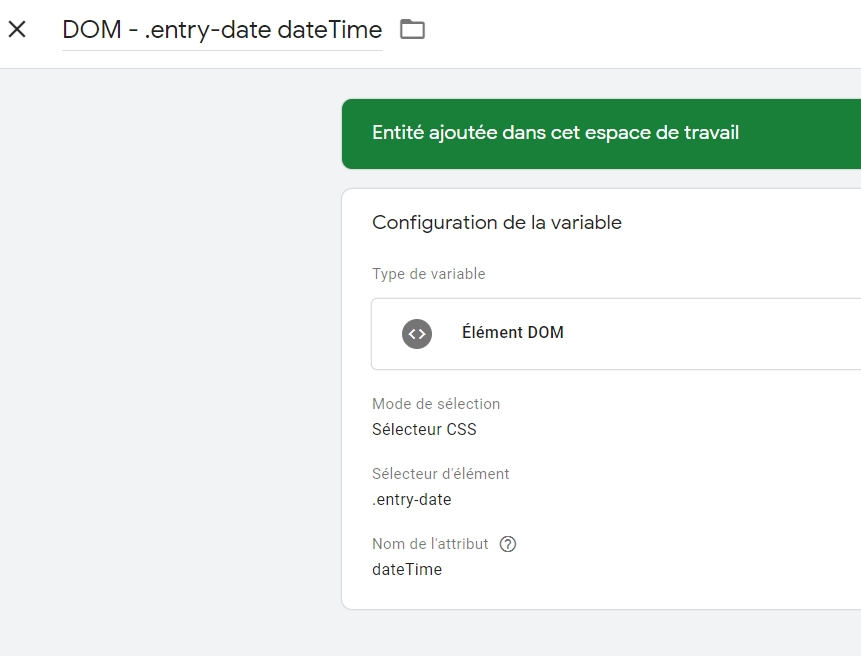
Voyons ce qu’on a côté Preview :

Bon, ce n’est pas encore ça côté format. Encore un petit effort avec un retraitement en JS :
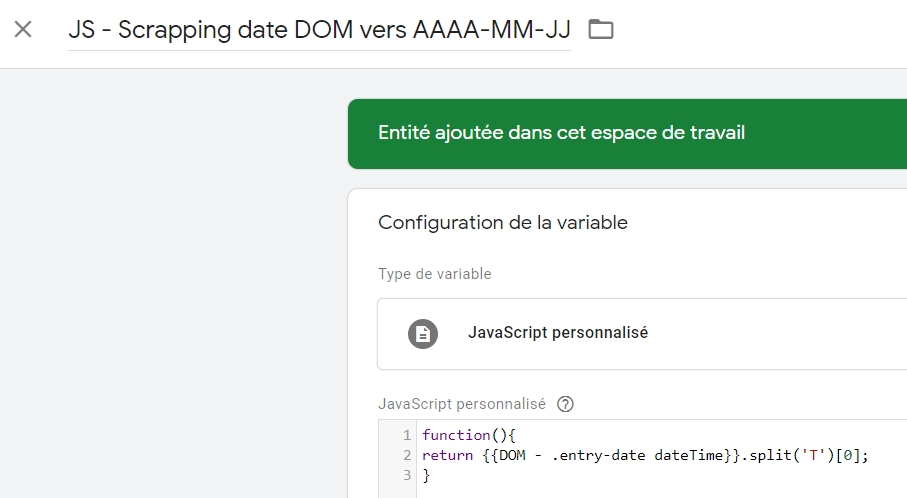
function(){
return {{DOM - .entry-date dateTime}}.split('T')[0];
}
Et voilà! C’était pas si compliqué finalement.
(Oui, un jour, je ferai un article sur le DOM scrapping, on dira ce qui est bien et ce qui n’est pas bien, et on rigolera sans doute pas mal. Mais laissez-moi d’abord finir mon article).
Pour aller plus loin
Si cette mécanique peut sembler très orientée sites édito, on peut tout à fait imaginer appliquer ça à du e-commerce, en remontant une date d’entrée / update d’un produit en base de données (est ce qu’un produit qui a été mis en ligne pour les soldes 2019 continue de performer?), et surtout, aller remonter ça dans une custom dimension de scope produit, et donc avoir tout ce qui va bien côté taux de conversions & cie. Le bonheur. Enfin, une certaine conception du bonheur.
Pour revenir au pur édito, a noter qu’il est aussi tout à fait possible de faire exactement la même chose sur non pas la date de publication, mais la date de dernière modification, les 2 n’étant d’ailleurs absolument pas incompatibles.
Conclusion
J’espère que cet article vous a donné des idées (ou à défaut vous a un peu fait rire), que vous travailliez pour un site édito ou non. Comme de coutume, n’hésitez pas à partager en commentaires (là, là, juste en-dessous) ou sur Twitter.
Tendresse, et kouign amann.