De tous temps, le SEO, avide de data, a été une dynamique fondamentale de la croissance webanalytique. En 1642, déjà, Enguerrand Ier, lors de sa légendaire campagne en Rhénanie Occidentale, s’écriait « Mil & vne manieres d’vtiliser Google Analytics povr le SEO. La marchandise qu’ilz portoyent et qu’ilz avoyent taggué et acheptée en la variable de Google Tag Manager et portoyent a Lymoges pour gagner vye ». Ou un truc dans le genre.
Mais trêve de plaisanterie ; après cette intro façon mauvaise composition d’histoire (excellent pour le SEO si je cherche à me positionner sur « Enguerrand Ier SEO », on sait jamais), parlons de ce qu’on va faire, concrètement, dans ce billet de blog que je m’apprête à écrire avec beaucoup de tendresse et de volupté : vous donner des conseils, simples à appliquer, vous permettant de disposer de meilleures infos liées au SEO dans Google Analytics, et ce (notamment) grâce à la surpuissance de Google Tag Manager.
Parce que oui, le SEO et la webanalytics, au fond, on ne va pas se mentir, on est quand même souvent copains. Autant, la perspective de fournir à une bonne vieille agence média à l’ancienne le taux de rebond de ses campagnes est souvent un sujet qui te calme un séminaire marketing (« Nan mais allô quoi, les impressions c’est largement suffisant pour faire de la notoriété »), autant un expert SEO qui se respecte aura toujours comme premier réflexe de mettre son nez dans Google Analytics pour voir les impacts de ses changements (backlinks, optimisations techniques, rédaction de contenu…) sur le trafic et le comportement des utilisateurs.
Je ne vais pas faire l’affront de détailler les bases (source de trafic « organic », pages de destination, association de GA et de la Search Console), je pars du principe que vous connaissez déjà tous ces fondamentaux. Non. Ce que je veux partager, c’est un ensemble de petites astuces plus avancées (mais au fond pas bien complexes), aussi bien côté Google Analytics que Google Tag Manager, qui vont vous faciliter la vie, et vous permettre de mieux analyser l’impacts de changements faits pour faire plaisir aux crawlers gentils visiteurs de votre site.
Les astuces vont, dans l’idée, de la plus simple à la plus complexe, donc, surtout, n’hésitez pas à picorer dans ce qui vous intéresse selon votre niveau de connaissance de GA/GTM.
Sommaire :
- Utiliser le channel grouping pour optimiser vos rapports
- Les custom dims qui sauvent la vie en SEO : l’exemple de la meta robots
- D’autres custom dimensions utiles
- Modifier le contenu de votre site grâce à GTM #nsfw
- Tracker les sites qui scrappent votre contenu
Utiliser le channel grouping pour optimiser vos rapports
Isoler le trafic SEO, que ça soit via les rapports de source et/ou des segments, en principe, pas de souci, on maîtrise. La source « organic », avec le medium qui correspond au moteur de recherche (« Google », « Bing »…), c’est un classique :
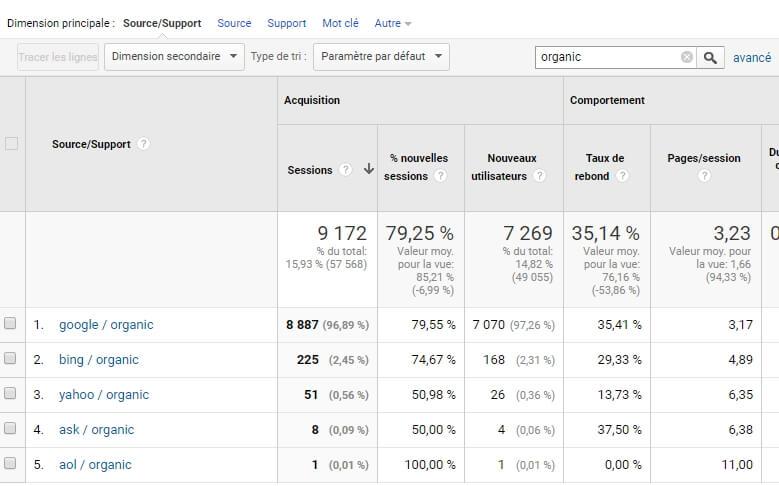
En revanche, lorsqu’on s’intéresse à une source de trafic en particulier comme le SEO, la granularité au niveau mot clé n’est malheureusement plus disponible (le not provided, tout ça, je ne vais pas remuer le couteau dans la plaie #rip).
Ce qu’on aimerait bien avoir, à défaut, c’est une sous-catégorisation du trafic SEO par « famille » de landing page, pour approximer vaguement ceci. Par exemple, dans le cas d’un site e-commerce : homepage (mots clés de marque), pages produits (mots clés par produit), pages de catégorie (mots clés par famille de produit).
Certes, le premier réflexe serait de faire un segment de ce type (dans le cas des familles de produits)…
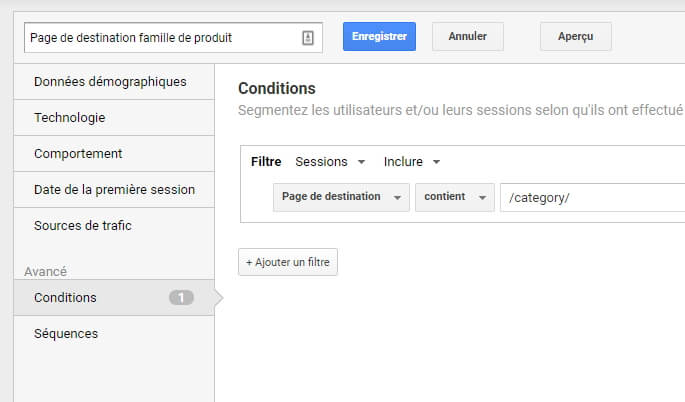
…mais il faudrait, dans notre cas, faire au total 3 segments, un par famille de landing page.
Pas cool.
C’est là que le channel grouping (ou « groupes de canaux ») va venir à notre rescousse. Le principe est d’une simplicité extrême : combiner les informations liées aux sources de trafic (Source, Support, Campagne, etc…) et d’autres dimensions de GA (en particulier la page de destination) pour créer des « paquets » de sources, qui vont répondre à votre besoin plutôt que de s’en tenir rigoureusement aux dimensions brutes de GA.
Pour cela, nous allons commencer par nous rendre dans l’admin de GA, au niveau de la vue, et nous rendre dans « Paramètres des canaux / Groupes de canaux » :
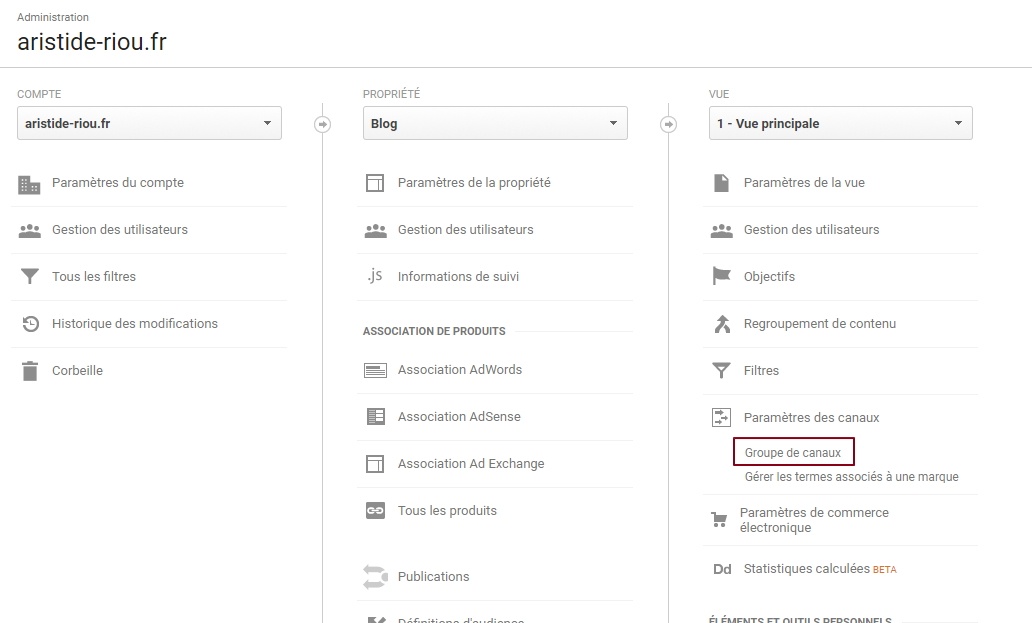
Ensuite, nous allons définir des règles pour nos « sous-paquets » liés au SEO, comme ceci (j’ai légèrement adapté par rapport au compte sur lequel j’ai pris les screenshots) :

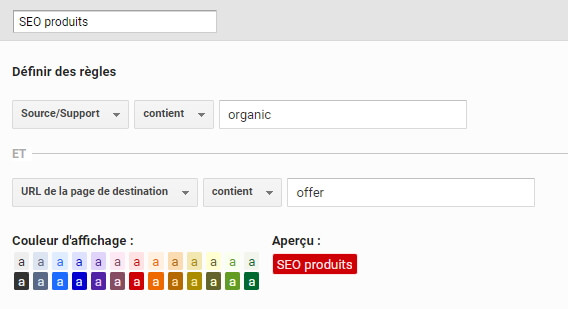
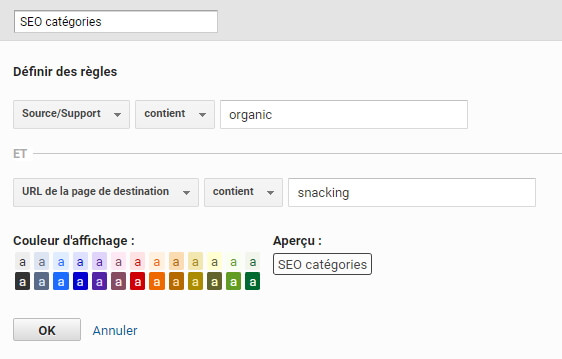
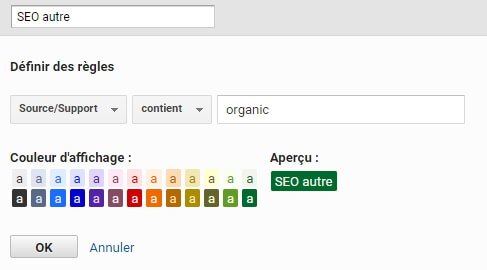
Notion fondamentale du channel grouping : les règles sont appliquées de haut en bas (et vous pouvez faire glisser les différents groupes pour les modifier une fois créé). C’est bien pour ça qu’il est crucial que notre 4ème canal (« SEO autre ») soit placé en dernier, car sinon, il prendrait le dessus sur les 3 autres, étant plus générique.
Et la meilleure nouvelle, dans l’histoire, c’est que le channel grouping est rétroactif. Oui, vous avez bien lu, ré-tro-ac-tif. Fabuleux, non? Vous pouvez donc expérimenter sans crainte.
On peut directement aller voir, dans les rapports, la tête qu’ont les données : notre petite sauterie va donc se passer « Acquisition / Tout le trafic / Canaux ». Fuyez le channel grouping par défaut, et empressez-vous de sélectionner le votre, tout beau tout neuf :
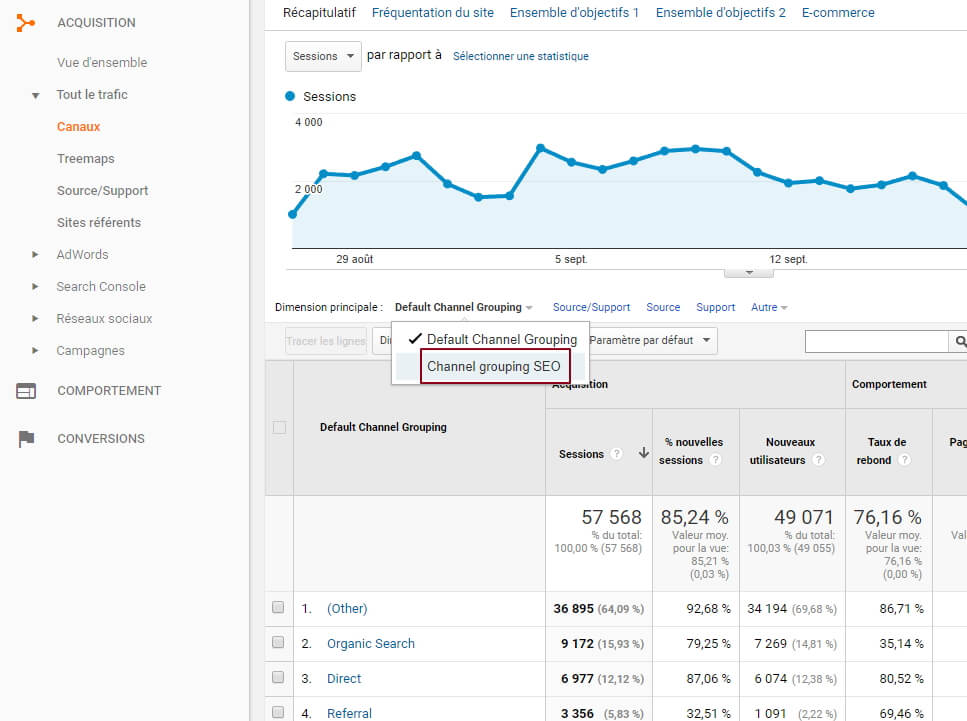
Tadaaaam!
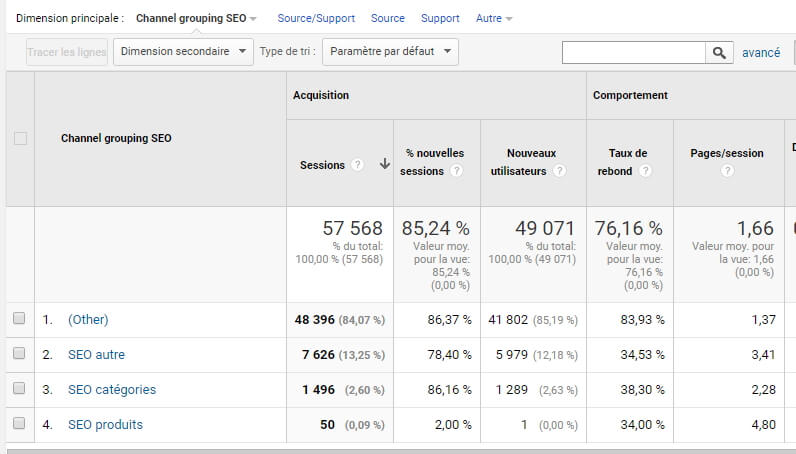
Comme on peut le voir, c’est « Other » qui remonte en premier. Normal, puisqu’ici, il s’agit de trafic « non SEO », qui ne rentre dans aucun de nos « paquets », donc, pas de panique. Vous pouvez même utiliser un filtre pour exclure ce « other » et avoir votre vision purement SEO. En revanche, nos autres catégories apparaissent bien dans le rapport.
Il est possible, évidemment, d’utiliser le channel grouping pour tout un tas de cas, en combinant des conditions sur le device, la « récurrence » de la session, j’en passe, et des meilleures. #theSkyIsTheLimit
En soi, vous pouvez obtenir ces informations de plein d’autres manières, mais le channel grouping a comme avantage essentiel de consolider la data d’une façon personnalisée et lisible, et surtout d’être rétroactif. A consommer sans modération, donc.
Les custom dims qui sauvent la vie en SEO : l’exemple de la meta robots
Si vous n’êtes pas familiers des custom dimensions (sachez que j’ADORE les custom dimensions #runningGag), voici le concept en deux mots : GA, durant toute session, va attribuer différentes caractéristiques aux utilisateurs (navigateur, OS, source de trafic…), mais aussi à leurs pages vues et événements qui vont survenir durant leurs sessions (nom de la page, titre de page, catégorie d’événement…).
En général, dans les rapports de GA, les dimensions sont affichées en lignes, par opposition aux metrics (ou « statistiques », dans la parfois étrange traduction française de GA), qui sont affichées en colonnes (pages vues, sessions, taux de rebond…).
Si on prend un exemple très simple, comme le rapport « Source/Support », on voit apparaître les différentes dimensions en ligne (par exemple le combo « google/organic »), puis les metrics associées à ces dimensions en colonnes (par exemple, le nombre de sessions, ou le taux de rebond).
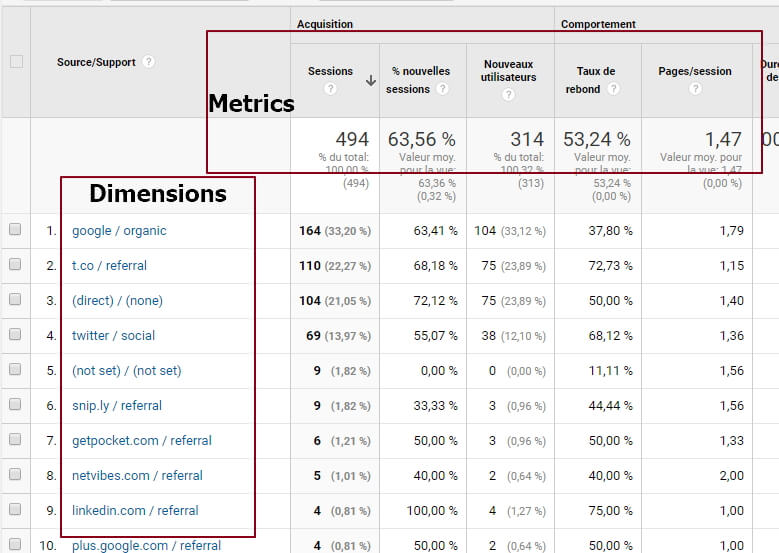
Bien, tout le monde a compris le truc? Ainsi, l’idée d’une custom dim (j’adore les custom dims), c’est donner à une page, une session, ou carrément à l’utilisateur, une information dont ne dispose pas nativement GA.
Par exemple, pour un article sur un site éditorial, on va souvent chercher à mettre en place des custom dims comme la rubrique, le fil d’ariane, ou encore l’auteur. Une custom dim est envoyée, dans ce cas, en surcharge du tag de page.
L’idée, dans notre cas, va être de surcharger nos tags de page avec des informations de nature plus technique, qui vont nous servir pour qualifier notre beau site d’un point de vue SEO. Et le plus beau dans l’histoire, c’est que le bouzin ne nécessitera pas une micro seconde de dèv, puisqu’on va passer par mon outil préféré, j’ai nommé AT Internet Google Tag Manager.
#instantPromo : si GTM ne vous parle absolument pas, je vous incite vivement à lire ce tuto merveilleurx que j’ai écrit et qui vous apprendra à devenir un champion inter-régional de l’outil.
Que diriez-vous de pouvoir récupérer les valeurs suivantes pour chacune de vos pages :
- Le statut de la meta robots
- La meta desc et/ou la longueur de ladite meta desc
- Le nombre de h1, h2, etc…
- Le protocole (HTTP/HTTPS)
Eh bien, pauvres mortels, vous n’êtes plus qu’à quelques encablures (en l’occurrence, quelques variables GTM) de l’accès à l’allégresse infinie.
Prenons donc, pour commencer, un simple tag de page Google Analytics paramétré dans GTM. Ne nous prenons pas trop la tête avec celui-ci, il s’agit d’un simple tag, sans rien de bien extraordinaire.
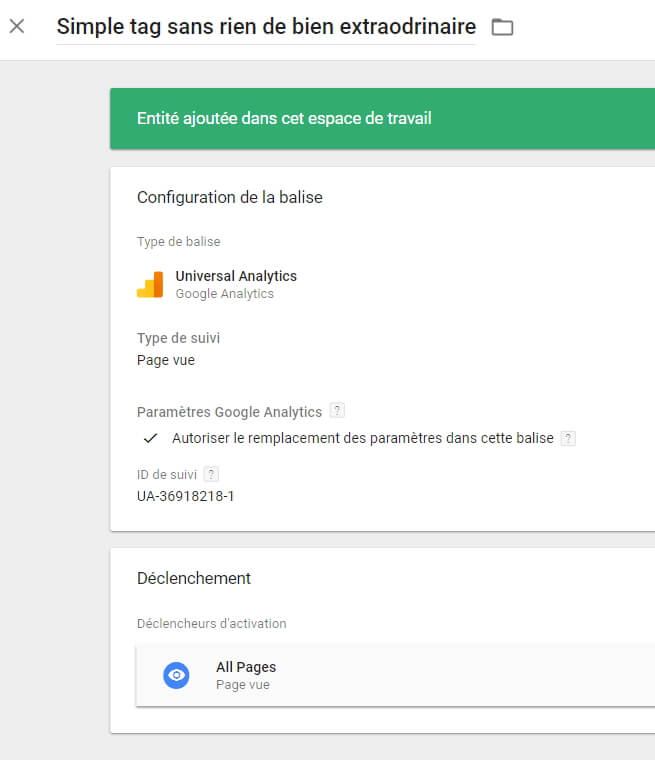
On peut se rendre sur cette page de démo pour vérifier que notre tag se déclenche correctement grâce au plugin WASP, par exemple.

Maintenant, nous allons laisser ce tag tranquille (après tout, il n’a rien demandé à personne) et travailler de façon autonome sur nos variables.
Commençons par créer celle qui nous permettra de connaître la meta robots :

function(){
var rob = 'index,follow';
//Dans le cas où la page ne comporte pas de meta robots, on la définit avec le comportement par défaut face au Googlebot
if(document.querySelector('meta[name="robots"]')){
rob = document.querySelector('meta[name="robots"]').content;
//Si la page comporte une meta robots, on la lit
}
return rob;
}
Rien de bien extraordinaire, on embarque, comme pour toute variable custom, notre JS dans une instruction function…return, et on va chercher la meta robots grâce à un petit querySelector de derrière les fagots.
Comme nous avons appris à le faire sagement, regardons tout d’abord comment se comporte cette variable grâce au merveilleux volet de preview GTM :
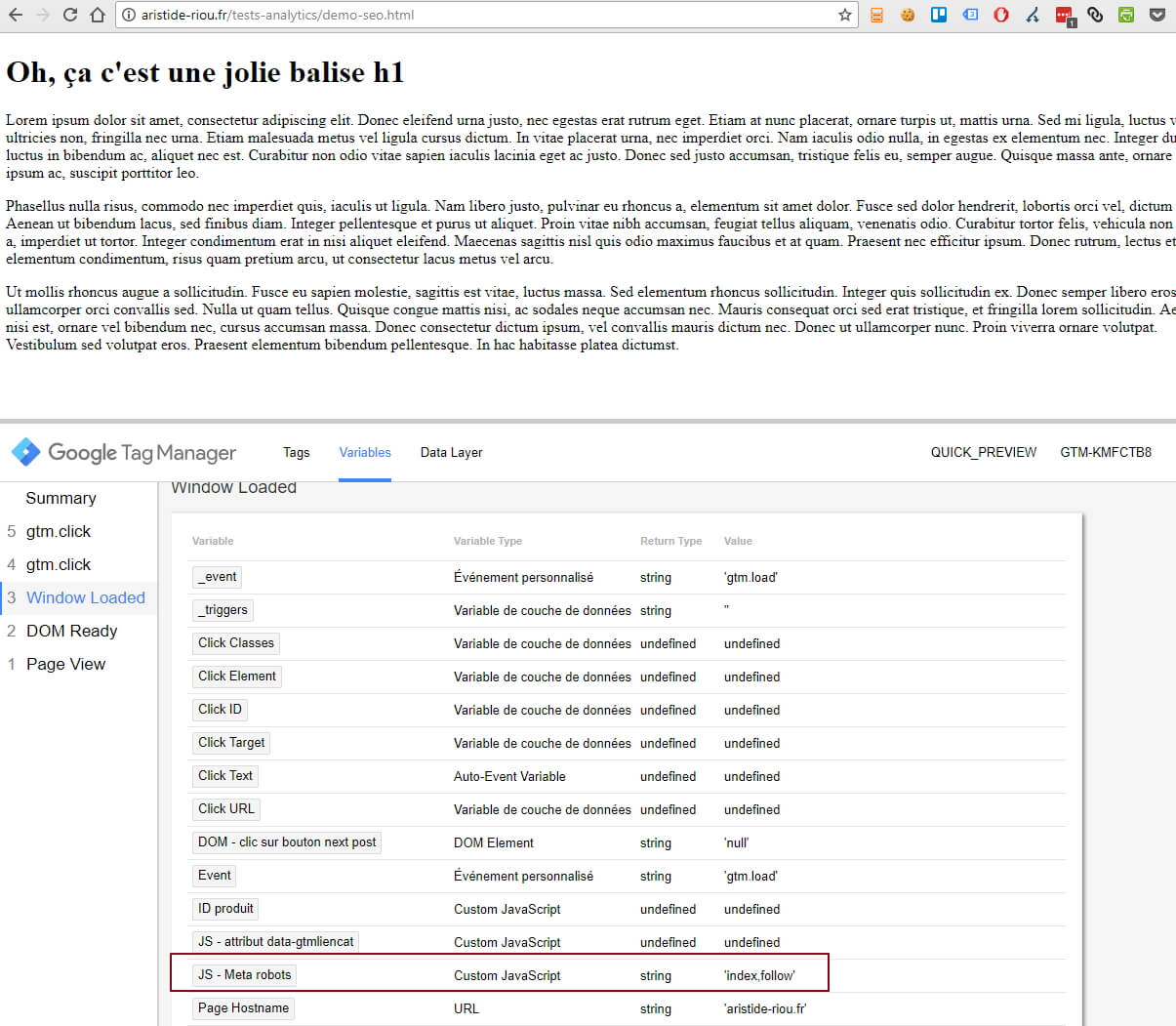
Pas de surprise, il s’agit d’une banale page de démo sur laquelle je n’ai rien spécifié en particulier concernant les robots, donc c’est la valeur par défaut qui remonte.
Après, notre variable en elle-même ne sert pas à grand chose pour le moment. Il va donc falloir retourner à notre tag de page (celui qu’on a laissé tranquille tout à l’heure), et coller ladite variable dans une custom dim :
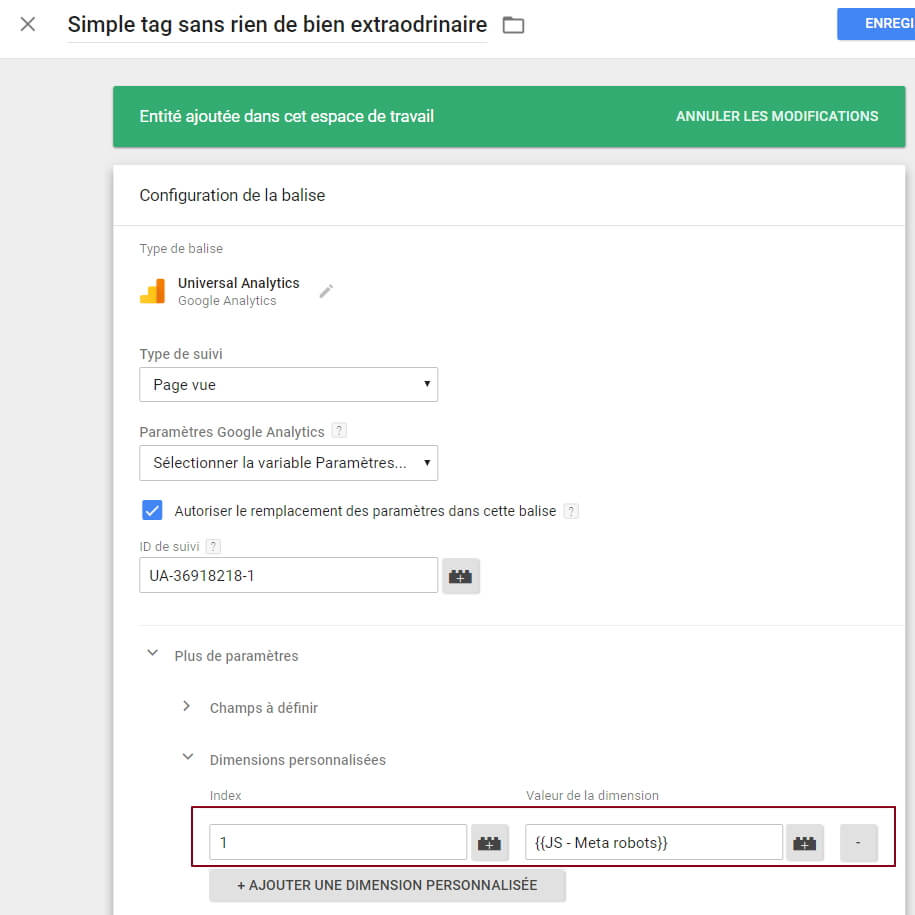
Evidemment, l’index de la CD doit correspondre à ce que vous avez défini dans votre admin GA (ici, 1) :
On peut se rendre sur la page de démo en question pour vérifier, par la suite, que notre tag de page remonte désormais correctement surchargé avec la custom dim qui va bien :

Imaginons maintenant que nous passions dans une faille spacio-temporelle tout à fait classique (publication GTM, des milliards de sessions déchaînées sur votre site), pour voir comment cela va remonter, concrètement, côté GA.
Vu que nous sommes des warriors, des vrais, des durs, on va direct se la donner, et se taper un bon gros custom report des familles.
Pour ça, il suffit de se rendre dans le rapport « Personnalisation / Rapports personnalisés », et de créer un nouveau rapport de la sorte :
On se retrouve ainsi avec un rapport de ce type :
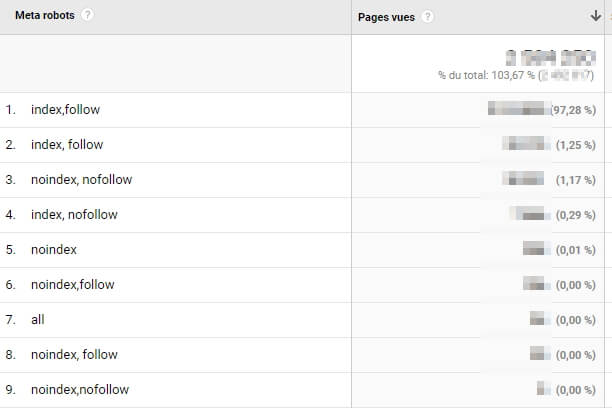
Côté metrics, j’ai gardé l’essentiel (pages vues, taux de sortie), mais il est bien évidemment possible de rajouter tout un tas de choses (consultations uniques, entrées…). Idem, on peut tout à fait faire un breakdown sur une autre dimension (native ou custom), comme le device ou la source de trafic.
Autre façon de récupérer les custom dims, en tant que dimension secondaire dans un rapport standard. A tout hasard, Rendons nous sur le classique « Comportement / Contenu du site / Toutes les pages », si on veut par exemple récupérer le top 10 de ses pages en nofollow, en termes de pages vues.
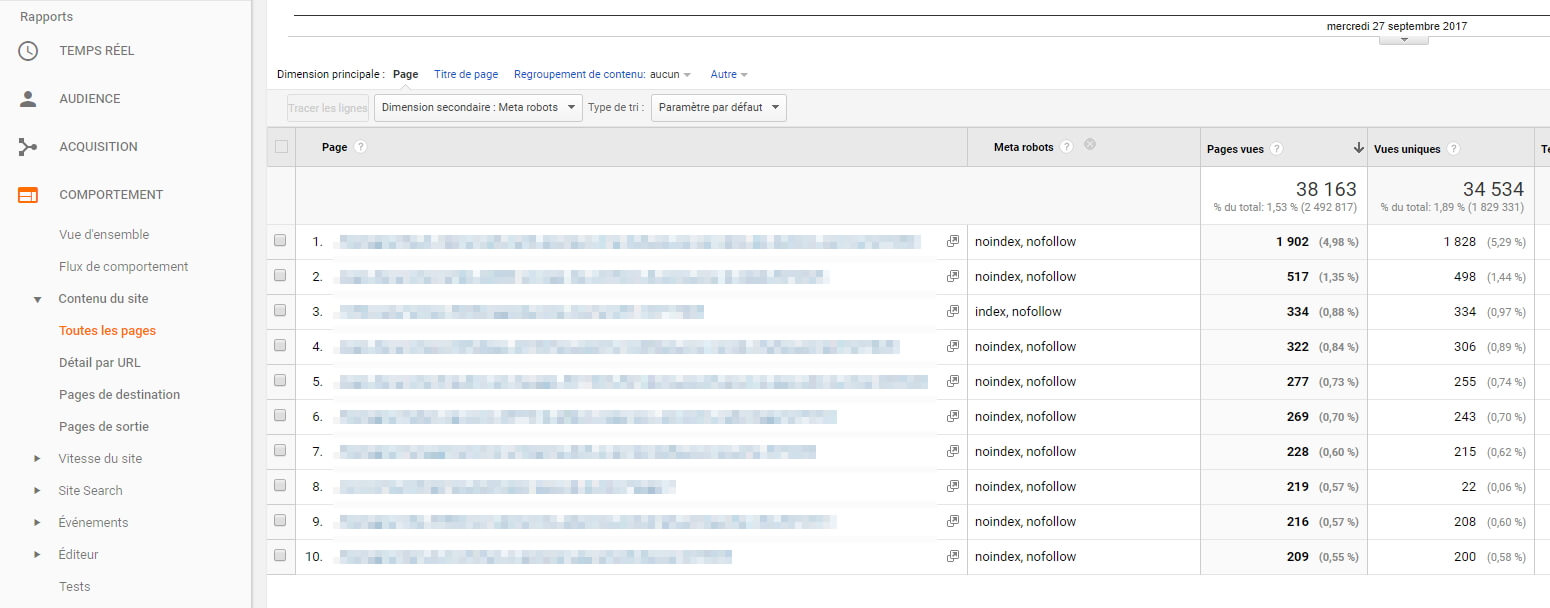
Alors, oui, on ne va pas se mentir, GA n’est pas là pour remplacer un outil d’analyse de logs comme OnCrawl ou Botify. Ce n’est pas parce que GA vous remonte 1 000 pages en nofollow que vous avez exactement cette quantité de pages en nofollow. Cela reflète simplement les pages qui ont été réellement vues par vos utilisateurs. En revanche, il est toujours intéressant (mais chronophage) de corréler ces deux sources de données, pour, par exemple, prioriser des chantiers sur la base de données de trafic.
D’autres custom dimensions utiles
J’ai donné toute la démarche dans les détails concernant notre meta robots, et je vois déjà vos yeux se remplir d’envie à l’idée de faire plein d’autres choses. Normal, le principe est exactement le même : variable GTM, custom dim dans GA, et surcharge de son tag de page.
Voyons donc de quoi il en retourne pour quelques autres variables qui peuvent être fort pratiques :
Longueur de la meta desc
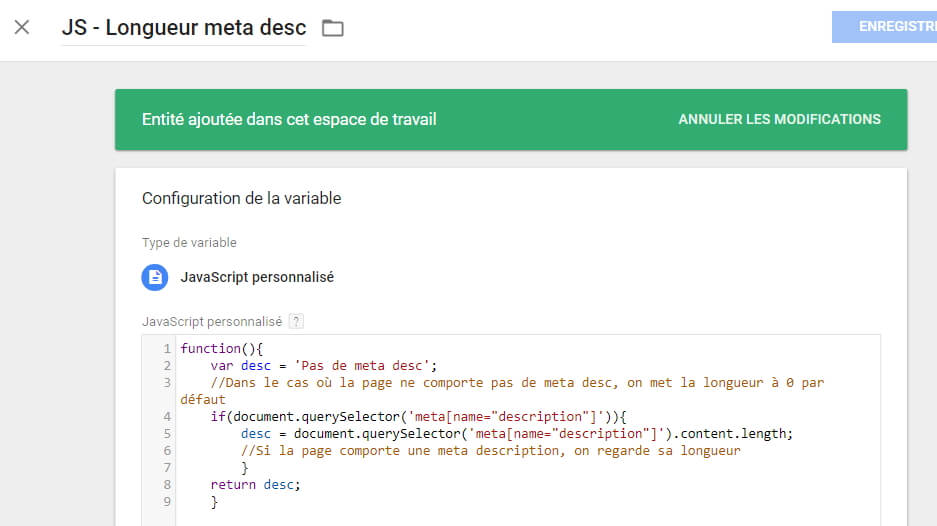
function(){
var desc = 'Pas de meta desc';
//Dans le cas où la page ne comporte pas de meta desc, on met la longueur à 0 par défaut
if(document.querySelector('meta[name="description"]')){
desc = document.querySelector('meta[name="description"]').content.length;
//Si la page comporte une meta description, on regarde sa longueur
}
return desc;
}
Hreflang

function(){
var lang = 'Pas de hreflang';
//Dans le cas où la page ne comporte pas de hreflang ES, on met une valeur par défaut
if(document.querySelector('link[hreflang="es"]')){
lang = document.querySelector('link[hreflang="es"]').href;
//Si la page comporte une hreflang ES, on la récupère
}
return lang;
}
Ici, à noter que l’on a été au plus simple en récupérant le contenu de la Hreflang ES, que l’on peut imaginer mettre dans une custom dimension, au même titre que ses copines hreflang DE et IT (par exemple). On pourrait tout à fait ne pas prendre en compte son contenu, mais remonter une concaténation de toutes les balises hreflang qui existent sur la page, en les séparant par des pipes (FR|DE|IT…).
Canonical

function(){
var can = 'Non défini';
var links = document.getElementsByTagName("link");
for (var i = 0; i < links.length; i ++){
if (links[i].getAttribute("rel") === "canonical"){
can = links[i].getAttribute("href");
}
}
return can;
}
Protocole
Cette fois, ne nous cassons pas la tête à mettre en place une variable custom, puisque le protocole est nativement accessible dans GTM :
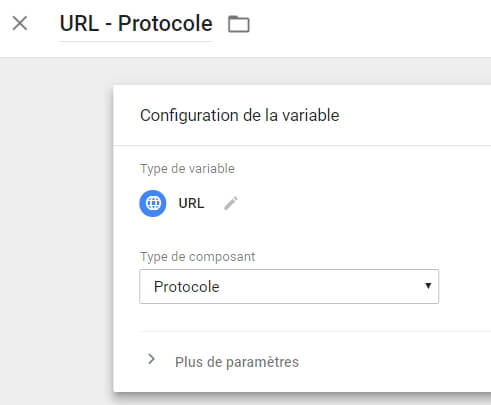
Très utile à mettre en place pour suivre une migration HTTPS (les personnes concernées se reconnaîtront)!
Si vous avez implémenté plusieurs de ces custom dimensions via GTM, n’hésitez pas à les croiser dans des custom reports GA, cela peut vous donner une finesse d’analyse très smooth : par exemple, le fait de chercher si les pages avec une canonical posent un problème de meta robots (et accessoirement, ont un taux de sortie inquiétant) peut être géré en un simple custom report.
Il existe énormément de cas d’utilisation de custom dims pour le SEO (et pas que, d’ailleurs), donc n’hésitez pas à abuser de celles-ci pour enrichir vos analyses.
Après, même si je ne veux pas jouer le gars qui vient gâcher la soirée, n’oubliez pas que, si vous n’avez pas la chance d’être sur GA360, vous êtes limités à 20 custom dimensions par UA et que, croyez moi, ça va vite. Choisissez donc avec parcimonie celles que vous utilisez, et surtout, n’hésitez pas à les désactiver / remplacer si elles ne vous servent plus.
Casser Modifier le contenu de votre site grâce à GTM #nsfw
Attention spoiler alert : on passe dans les choses plus tout à fait catholiques côté Google Tag Manager : modifier à la volée le contenu du site.
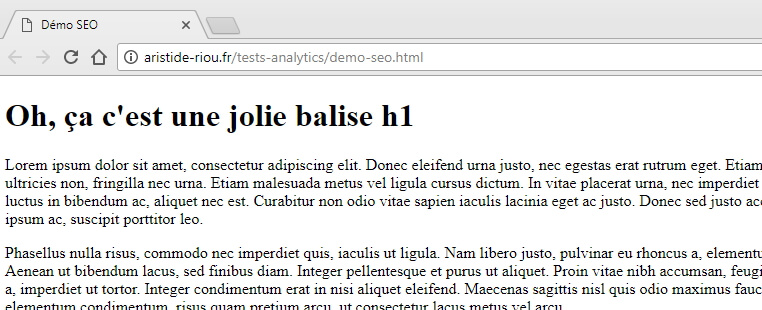
Après tout, si on prend un peu de recul, GTM n’est rien d’autre qu’un injecteur Javascript. Récupérer le contenu d’une ou plusieurs balises et les réecrire, il n’y a rien de plus simple. Imaginons par exemple que les balises title répondent à un pattern particulier sur un site, pattern que vous ne trouvez pas optimal d’un point de vue SEO. Imaginons maintenant que vous souhaitiez prendre la title telle qu’elle est définie actuellement, et y ajouter la h1. Dans le cadre de notre page de démo, l’idée serait donc d’aboutir à une title qui vaut « Démo SEO | Oh, ça c’est une jolie balise h1 » (oui, je sais, ça n’a aucun sens, mais faites moi plaisir, imaginez que c’est une vraie optimisation).
L’idée va être d’exécuter un tag de type « HTML personnalisé » qui va faire ce travail tout seul, comme un grand :
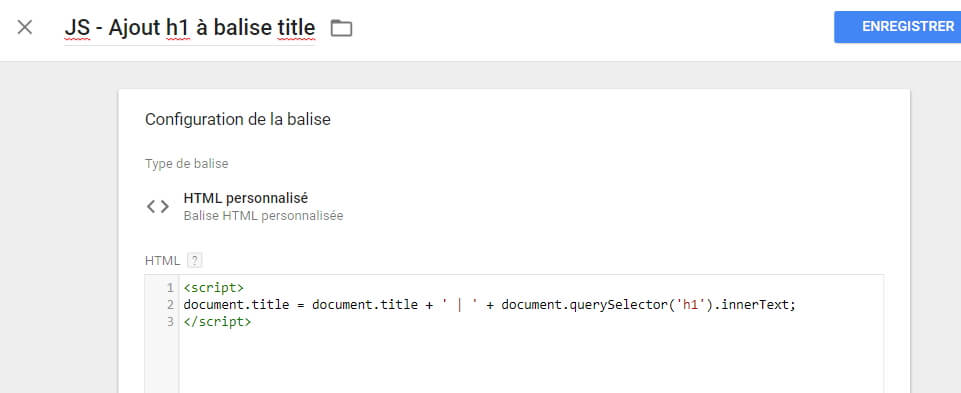
<script>
document.title = document.title + ' | ' + document.querySelector('h1').innerText;
</script>
#proTip : j’attire votre attention sur le trigger à utiliser. Préférez un tag de type « Page vue », plutôt que « DOM prêt » ou « Fenêtre chargée », dans la mesure où cela fera partir votre modification dés que le snippet Google Tag Manager sera lu, et sera donc en principe moins perceptible par l’utilisateur.
(après, il faut éviter autant que possible le trigger « all pages », mais ça, vous le savez déjà (voir astuce No 11))
On peut voir très rapidement l’effet flickering apparaître lors d’un refresh de la page :

L’expérience a montré que Google prenait ces changements en compte (je ne vous apprend rien, le Googlebot exécute de plus en plus le JS des pages).
Ici, j’ai pris un exemple extrêmement simple, mais j’imagine que vous saisissez tout le potentiel de la chose : changer des h1, toutes sortes de meta, voire carrément ajouter / modifier du contenu (et même faire de l’AB testing, mais c’est un autre sujet). Le principe sera globalement le même : un sélecteur malin pour récupérer le contenu en question, et factoriser intelligemment ses scripts en trouvant un pattern suffisamment générique (comme c’est le cas avec mon exemple très bas du front).
Donc c’est le genre de chose qui peut être intéressante à mettre en place dans le cadre d’un POC lorsque faire un dèv est un peu compliqué, mais dans l’absolu, vous comprenez en quoi ce n’est pas une démarche durable : si Google indexe de mieux en mieux le JS, ce n’est a priori pas le cas de la plupart des autres moteurs (plus d’infos ici). Sans compter que crawler du JS a un coût supplémentaire pour un robot, et je ne vais pas vous faire le coup du crawl budget (c’est, dans une certaine mesure, le même type de débat que pour les sites en SPA, mais je m’égare).
Enfin, gérer ce genre de changements à la volée peut induire une grosse dépendance vis à vis de la structure de la page, et donc, casser du jour au lendemain pour une raison qui n’a rien à voir.
Si vous voulez plus de ressources sur le sujet, n’hésitez pas à consulter l’article de Moz qui détaille nettement plus la méthodo, ainsi que le deck de la conférence de Sébastien Monnier, qui en a parlé récemment à la conférence Brighton SEO.
Tracker les sites qui scrappent votre contenu
Il y a quelques mois, au MeasureCamp de Paris, j’avais partagé une astuce qui est un grand classique de GTM, à savoir qu’il faut éviter d’utiliser le trigger par défaut qui est proposé à la création d’un tag, à savoir « All Pages »
En effet, en vieux briscards du SEO que vous êtes, vous savez à quel point il est courant, notamment pour un site à fort trafic, de se faire scrapper sans vergogne son contenu, qui est ainsi exécuté sur un domaine bidon. Ainsi, lorsque le contenu scrappé comporte votre container GTM, et que vos tags sont conditionnés par un trigger « All Pages », ils seront également exécutés depuis le domaine « scrappeur ».
Plus d’infos dans cet article, astuce 11.
(A noter que c’est un peu la même problématique que pour la question d’utiliser des liens en absolu ou en relatif).
Or, lors de la conférence, le légendaire mais fort cordial JB Gabellieri me faisait remarquer qu’en soi, cette information pouvait tout de même être utile. En effet, pourquoi ne pas avoir une info, isolée proprement, des sites qui scrappent votre contenu, avec des infos d’analyse au même titre que pour vos « vraies » pages : quelles sont les pages les plus scrappés, combien de pages sont vues, est ce que je pourrais quand même pas déclarer ça à l’OJD?
La manipulation, pour le coup, est tout ce qu’il y a de plus simple : conditionner vos tags GA par un trigger « All Pages » (je vous épargne le screenshot, ça devrait bien se passer), puis faire un filtrage propre au niveau de GA, en gardant comme d’habitude une vue « brute » (ça dépanne toujours), puis en faisant 2 vues incluant / excluant ces domaines scrappeurs :
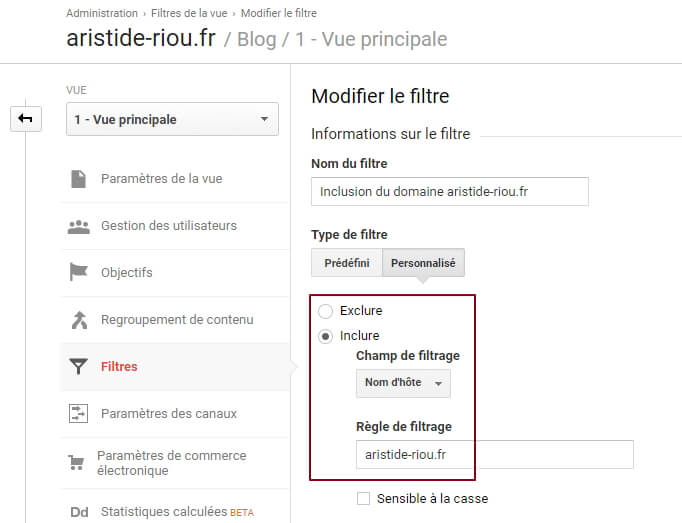
On peut même imaginer faire une vue dédiée à un site scrappeur en particulier, histoire de lui péter les genoux pouvoir lui envoyer un beau recommandé.
Alors, attention, bien entendu, cette technique comporte une certaine part de risque : en effet, nul n’est censé ignorer que le volume de scrappers qui s’amusent à reprendre gentiment le contenu de votre site peut vite devenir très important. Si vous n’êtes pas sur GA360 (et d’ailleurs, même si vous êtes sur GA360, hein, bordel), surveillez attentivement le volume de hits que ces sites fantômes génèrent.
Il existe cependant une technique alternative, un chouïa plus complexe mais intéressante : utiliser un routeur d’UA, via une variable dans GTM, pour envoyer vos tags sur un UA dédié si le tag est appelé sur un domaine autre que le site « ordinaire ».
Cette variable est tout ce qu’il y a de plus simple à mettre en place :
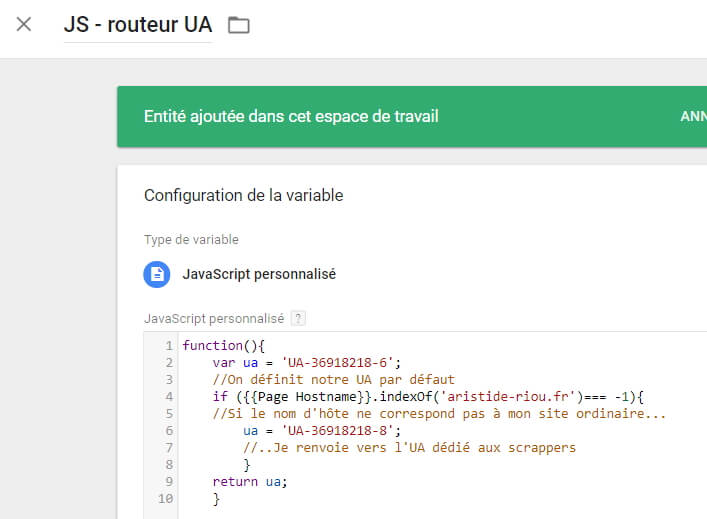
function(){
var ua = 'UA-36918218-6';
//On définit notre UA par défaut
if ({{Page Hostname}}.indexOf('aristide-riou.fr')=== -1){
//Si le nom d'hôte ne correspond pas à mon site ordinaire...
ua = 'UA-36918218-8';
//..Je renvoie vers l'UA dédié aux scrappers
}
return ua;
}
En grands professionnels que nous sommes, nous pouvons rapidement vérifier, grâce au volet de preview GTM, que la variable est évaluée correctement :
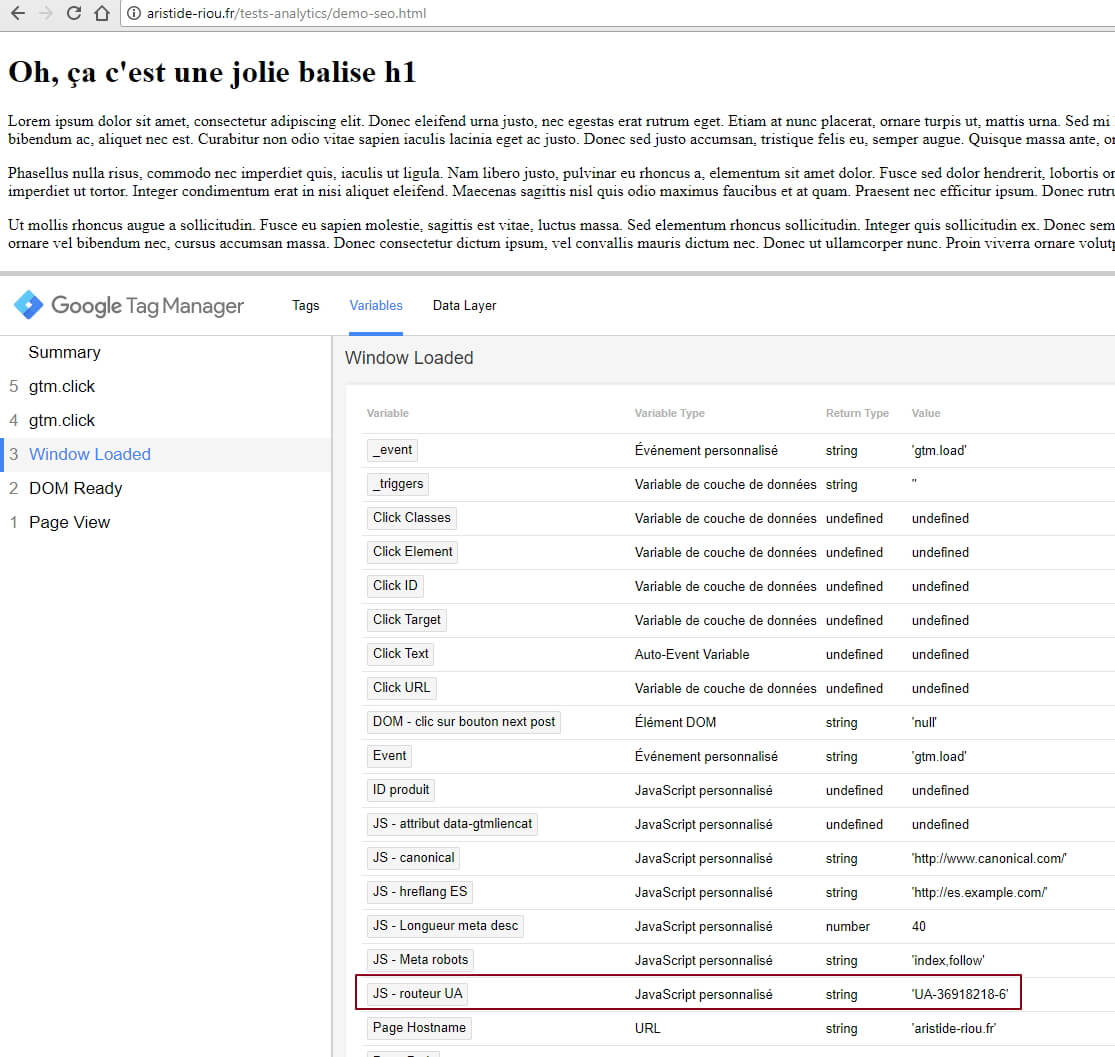
Parfait, maintenant, il ne reste plus qu’à l’embarquer dans notre tag de page (ou encore dans une variable « Paramètres Google Analytics », mais c’est un autre sujet) :

Et voilà une affaire qui tourne! Maintenant, plus de crainte de polluer un UA avec des risques d’échantillonnage ou de données qui ne reflètent pas réellement le comportement de vos utilisateurs.
A noter que cette technique peut être appliquée selon le même principe sur le paramètre « robots » de Google Analytics :
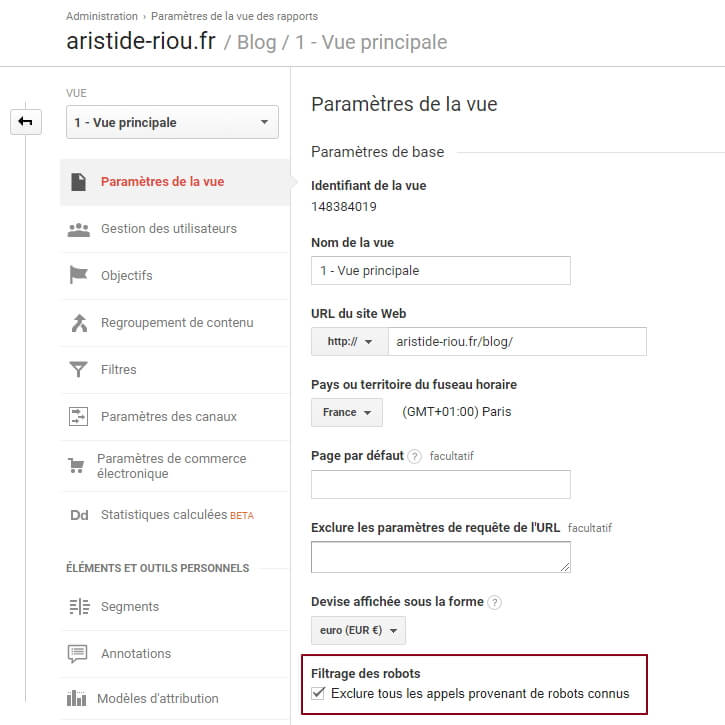
S’il est bien évidemment conseillé de cocher cette case, on peut tout à fait dupliquer une vue quelconque en ne cochant pas la tickbox, et voir le différentiel. En revanche, il n’est pas possible d’isoler les robots à proprement parler (il n’y a pas de case « n’inclure que les robots » dans l’admin GA, il ne faut pas non plus déconner).
Conclusion
J’espère avoir pu vous aider à mieux maîtriser des petites subtilités de GA/GTM afin de pouvoir mieux analyser vos actions SEO. Comme d’habitude, si vous avez des questions, des remarques, ou que vous voulez juste dire à quel point mon blog est un cadeau divin (on ne sait jamais), n’hésitez pas à commenter où à me contacter sur les internets.
Article intéressant et bien expliqué.
Pour info, tu remontes en 4e position sur « Enguerrand Ier SEO » 😉
Un grand merci Monsieur Saucisse pour votre commentaire.
Je pense que je dois choper des positions grâce à l’autorité de mon domaine. Je ne vois pas d’autre explication.
Vraiment top l’article, merci. En couplant la balise de robots.txt avec une alerte personnalisée il y a moyen de réagir très rapidement s’il y a boulette sur le site (genre noindex > 20% / la veille).
Sinon pour les mots clés je sais que certains utilisent le H1 en dimension personnalisé et ça leur donne une idée de mot clé tapé par page. Bon ça nécessite d’avoir de bons H1 par contre…
Merci Vincent pour ton commentaire et tes encouragements !
Tout à fait, on peut inclure la h1, cela peut être utile. Il faut juste penser, dans la variable GTM, à prévoir le cas où il y en a plusieurs (chat échaudé…), et le cas échéant, les remonter avec un séparateur propre.
Exact concernant le H1, je fais la même chose mais avec le title 😉